
Literatuuronderzoek
Samenvatting van het literatuuronderzoek
1 Inleiding
In de berichtgeving rondom de coronacrisis, een actuele crisis ten gevolge van het coronavirus (COVID-19) is er veelal sprake van nepnieuws. Niet alleen worden er dubieuze verhalen gedeeld, er wordt ook foutieve gezondheidsinformatie verspreid rondom de herkenning van symptomen en de bestrijding van het coronavirus. Voorbeelden van dit soort artikelen zijn berichten die bijvoorbeeld stellen dat gorgelen met bleek het coronavirus zou doden of dat huisdieren het virus zouden overdragen. Als dit soort berichten worden gedeeld, heeft dit logischerwijs een enorme impact op het verloop van de crisis, zo niet een rol in kwesties van leven of dood. Met het oog op de maatschappelijke relevantie van het herkennen van nepnieuws, is het nuttig om inzicht te verkrijgen in nepnieuws als fenomeen en onderzoek naar nepnieuws. Aan de hand van een combinatie van kwalitatief en kwantitatief onderzoek zal dit bereikt worden. Deze combinatie van kwalitatief en kwantitatief onderzoek biedt een compleet beeld van nepnieuws en biedt de onderzoekers een kans om op een interdisciplinaire en verdiepende wijze hun vak te beoefenen. Tijdens het opstellen van dit onderzoek hebben wij het antwoord moeten vinden op zes onderzoeksvragen, namelijk: wat is nepnieuws, wie verspreidt nepnieuws, hoe wordt nepnieuws verspreid, hoe combineer je kwalitatief en kwantitatief onderzoek, hoe kan een database gevormd worden en welk algoritme kan er gebruikt worden.
2 Wat is nepnieuws?
Om nepnieuws te herkennen, is het belangrijk om te weten wat nepnieuws precies is. Voordat de definiëring van nepnieuws behandeld kon worden, is er gekeken naar filosofische kwesties die ten grondslag liggen aan nepnieuws als fenomeen, namelijk: de rol van waarheid en de rol van bewustzijn. Hierbij is er aangenomen dat er waarschijnlijk geen absolute waarheid is, maar dat dit niet betekent dat objectieve verslaggeving is uitgesloten. Bovendien speelt intentionaliteit een belangrijke rol bij het onderscheiden van nepnieuws van foutieve informatie.
De definities van de behandelde artikelen bestonden uit verschillende aspecten, waarvan er drie zijn behandeld, namelijk: the degree of falsity, de verschijningsvormen van nepnieuws en mediaplatformen waarop nepnieuws verschijnt.
Uit the degree of falsity is gebleken dat nepnieuws geen eenduidend begrip is. Er is sprake van een verschil in mate aan ‘nepheid’: sommig nieuws kan nepper zijn dan ander nieuws. Dit betekent echter niet dat er geen sluitende definitie van nepnieuws kan worden gegeven.
Uit het analyseren van de verschillende verschijningsvormen van nepnieuws is gebleken dat er een smalle definitie en een brede definitie van nepnieuws kan worden opgesteld. De smalle definitie is als volgt: “Nepnieuws is het intentioneel produceren of bewust verspreiden van verifieerbaar foutieve informatie.” Deze definitie aangenomen, worden er minder verschijningsvormen van foutief nieuws onder nepnieuws geschaard dan bij de brede definitie, namelijk: fabricated news, propaganda, hoaxes, sommige vormen van satire en eventueel clickbait. Daartegenover luidt de brede definitie als volgt: “Nepnieuws is foutieve informatie”. Deze definitie aangenomen, worden alle verschijningsvormen van foutieve informatie onder nepnieuws geschaard.
Hoewel nepnieuws voornamelijk wordt gelinkt aan digitale mediaplatformen zoals sociale media, lijkt dit niet te worden beschouwd als een noodzakelijke voorwaarde van nepnieuws: nepnieuws komt zowel voor op traditionele media als digitale media.
Nepnieuws is een lastig fenomeen om te definiëren, maar aan de hand van de opgestelde definities kan er toch inzicht worden verkregen in dit fenomeen. Dit is niet alleen theoretisch waardevol, maar zal ook van pas komen in de praktijk bij het analyseren van nepnieuws rondom de coronacrisis. Voor ons onderzoek is het logisch om de smalle definitie van nepnieuws aan te nemen, omdat deze definitie veelvuldig wordt aangenomen in ander onderzoek naar nepnieuws. Aangezien er tussen onderzoekers onderling geen consensus is over de verschijningsvormen die per definitie onder nepnieuws kunnen worden geschaard, lijkt het verstandig om alle verschijningsvormen van foutief nieuws onder nepnieuws te scharen met het oog op het verzamelen van zoveel mogelijk data. Dit zal uiteindelijk de beste resultaten opleveren.
3 Wie verspreiden er nepnieuws?
Zodra het begrip ´nepnieuws´ duidelijk is, is de volgende logische stap om te kijken wie er nepnieuws verspreidt. Als er meer duidelijkheid is over de verspreiders van nepnieuws en hun motieven, kunnen deze mensen makkelijker worden opgespoord en kan er eerder een oplossing worden gevonden om de verspreiding van nepnieuws tegen te gaan.
Concluderend kan er gesteld worden dat nepnieuws door zowel software gestuurde programma´s kan worden verspreid, als door menselijke organisaties en individuen. Software gestuurde programma´s, oftewel social bots, hebben als doel om sociale wanorde te creëren. Dit doen ze door zeer gericht misleidende en manipulatieve berichten te plaatsen op sociale platformen, in de hoop gebruikers te beïnvloeden.
De menselijke actoren die nepnieuws verspreiden zijn politieke organisaties, overheden, journalisten, trollen en useful idiots. Zij verspreiden nepnieuws vanuit drie mogelijke motieven. Deze motieven kunnen politiek, financieel en sociaal van aard zijn en hebben als gemeenschappelijke factor dat ze de verspreiding van nepnieuws als einddoel hebben. Politieke organisaties en overheden kunnen nepnieuws verspreiden vanuit politieke motieven. Ze verspreiden nepnieuws omdat ze hun organisatie willen promoten, andere concurrerende organisaties in een slecht daglicht willen zetten of een specifiek verhaal naar het publiek willen brengen. Journalisten kunnen nepnieuws verspreiden vanuit financiële en sociale motieven. . Financieel, als ze met hun nep berichtgeving de verkoopcijfers van hun blad willen bevorderen en sociaal, als ze door nep berichtgeving de populariteit van hun platform, site of krant willen vergroten. Ten slotte zijn er ook nog trollen en useful idiots. Trollen zijn gebruikers van sociale platformen die bewust provocerende- of niet-relevante berichten plaatsen om andere gebruikers uit te lokken of emotionele druk uit te oefenen. Dit doen ze puur vanuit het sociale motief om chaos te schoppen. Useful idiots verspreiden, anders dan trollen, onbewust nepnieuws omdat ze nepnieuws uit onwetendheid aannemen als waarheid en vervolgens verspreiden.
3 Hoe wordt nepnieuws verspreid?
Het internet kan worden beschouwd als een netwerken met daarin allerlei kleine subnetwerken aan gebruikers. In elk (sub)netwerk zijn er slechts een aantal gebruikers die het grootste deel van de nepnieuws verspreiden. Een goed beeld van hun berichten geeft dus een aardig beeld van hun subnetwerk. Andersom zal een subnetwerk waarschijnlijk gedomineerd worden door berichten die zijn te herleiden tot een aantal gebruikers. Als het gaat om misinformatie lijkt dit effect versterkt. Verder volgen beide misinformatie en correcte informatie hetzelfde patroon qua deel gedrag. Voor beide geldt dat een groot deel van de berichten niet langer dan 2 uur worden gedeeld en de meeste niet langer dan een dag. Berichten met misinformatie waar veel interesse voor is worden langer gedeeld, terwijl berichten met correcte informatie waar veel interesse voor is niet per se langer worden gedeeld.
Hierom wordt er aangeraden om bij het kwalitatieve deel van het onderzoek te kijken naar de berichten waar veel interesse in is. Het liefst ook een bericht dat komt van een bron in het netwerk met veel invloed, deze zou geïdentificeerd kunnen worden a.d.h.v. een frequentie analyse op een groot deel van de berichten in een subnetwerk. Mocht dit niet lukken, dan kan er rekening mee worden gehouden dat berichten met weinig participatie waarschijnlijk niet representatief zijn voor het hele subnetwerk.
4 Hoe combineer je kwalitatief en kwantitatief onderzoek?
Om nepnieuws te identificeren zal er gebruik worden gemaakt van zowel een kwalitatieve als een kwantitatieve methode. Op deze manier kunnen de krachten van beide methoden samengevoegd worden in één onderzoek. Om tot de beste onderzoeksresultaten te komen zal er eerst kwalitatief onderzoek gedaan worden, gevolgd door kwantitatief onderzoek.
Bij het kwalitatieve onderzoek gaat het om het onderzoeken van de variatie van data op kleinere schaal. Schrijvers van nepnieuws willen hun lezers vaak misleiden door middel van overdreven uitdrukkingen en sterke emoties. Hier kan er gebruik worden gemaakt van het kwalitatief onderzoeken van teksten. Er zal eerst bepaalt moeten worden welke eigenschappen onderzocht willen worden en welke eigenschappen het meest kenmerkend zijn voor nepnieuws. Er kan gekozen worden voor attribute-based language features, die vooral gaan over de emotie in een tekst, of voor structure-based language features, die de inhoudsstijl van teksten analyseert op taalniveau. Aan beide aanpakken zitten voor- en nadelen. Zo is attribute-based onderzoek erg specifiek, maar moeilijk te kwantificeren, terwijl structure-based onderzoek makkelijk te kwantificeren, maar minder specifiek is. Wanneer de eigenschappen waarop getest willen worden gekozen zijn, kan het handmatig analyseren van teksten beginnen. Zowel nepnieuws als echt nieuws zal gecontroleerd worden, waardoor over beide teksten genoeg informatie hebben verkregen zal worden.
Wanneer het kwalitatieve onderzoek is afgerond, kan het kwantitatief onderzoek beginnen. Er is nu genoeg data beschikbaar over de kenmerken van nepnieuws en echt nieuws, waardoor nieuwe teksten hiermee vergeleken kunnen worden. Dit zal gebeuren door middel van een algoritme, dat de kennis bezit die verkregen is uit het kwalitatieve onderzoek. Deze kan kenmerken van nieuwe teksten vergelijken met zijn database, waardoor het algoritme nieuwe teksten kan bestempelen als nepnieuws of echt nieuws. Op deze manier kunnen grote hoeveelheden teksten kwantitatief gecontroleerd worden op echtheid.
Door het combineren van kwalitatief en kwantitatief onderzoek, kunnen de beste resultaten verkregen worden.
5 Hoe kan er een database opgesteld worden?
Om het kwantitatieve deel van het onderzoek uit te kunnen voeren, moet er zowel een dataset worden opgesteld, als een passend algoritme worden gekozen om deze te verwerken.
Het opstellen van een dataset zal een substantieel deel van dit onderzoek in beslag nemen. Er moet immers data worden verzameld en (deels handmatig) verwerkt. Tegelijkertijd moet er genoeg tijd overblijven om de algoritmes juist te trainen. Om een zo hoog mogelijke graad van automatiseren en dus tijdwinst te krijgen, zullen wij onze database baseren op tweets. Dit betekent dat al onze data al ongeveer van dezelfde lengte is en aangezien het ook vrij kort is, zal het makkelijker te verwerken zijn. Gelukkig is er op Twitter zowel veel nepnieuws als echt nieuws te vinden, maar moet iedere tweet wel worden gecheckt op waarheid door een van de onderzoekers. Wanneer de tweets worden verzameld, zullen ze door verschillende stadia van pre-processing gaan voordat de database kan worden gebruikt door een algoritme.
6 Welk algoritme kan er gebruikt worden?
Er zijn vele mogelijke algoritmes te gebruiken, waarvan er drie gedetailleerd zijn bekeken door de onderzoekers. Zo is er de kennisgraaf, waarbij het proces inzichtelijk blijft voor de programmeurs en welke echt gebaseerd is op de inhoud van een tekst, maar ook grote moeite kost om te implementeren. Voor dit onderzoek lijkt dit echter niet de juiste optie, aangezien de kennis over het coronavirus met grote snelheid is veranderd. Het succesvol vangen van de kennis over het virus en de aanpak ervan in een graaf lijkt daarom een opgave van een enorm formaat en misschien niet eens praktisch te realiseren.
Daarom is de focus verlegd naar Naive-Bayes en LSVM. Beide zijn algoritmen die zich baseren op schrijfstijl, waardoor de link met het kwalitatieve deel van dit onderzoek makkelijk te leggen is. Verder zijn implementaties van deze algoritmes makkelijk te vinden, wat de programmeurs veel tijd zal schelen. Helaas zijn beide algoritmes een zogenaamde black box, wat inhoudt dat de classificatie die wordt gemaakt niet geheel te verklaren is door de programmeurs.
Zowel Naive-Bayes als LSVM hebben ook hun eigen voor- en nadelen. Naive-Bayes is zeer bekend bij de programmeurs van dit onderzoek, is erg simpel te implementeren en kost relatief weinig tijd om te trainen, maar de nauwkeurigheid is vaak niet extreem hoog. Daarentegen is LSVM wel een ingewikkeld algoritme, maar kan het een extreem hoge nauwkeurigheid halen, maakt het snellere voorspellingen en biedt het de kans om met een nieuw algoritme te leren werken.
In plaats van een harde keuze maken tussen deze twee algoritmes, zullen wij beide implementeren. Hierbij zou Naive-Bayes als eerste geïmplementeerd worden, zodat er in ieder geval een werkend algoritme is. Wanneer dit is bereikt, kan de focus worden verlegd naar LSVM. Als beide algoritmes uiteindelijk werken, kan worden bekeken welk algoritme de hoogste nauwkeurigheid kan krijgen. Dit algoritme zal dan uiteindelijk het ‘eindproduct’ zijn.
Voor een uitgebreide bespreking van de onderzoeksvragen inclusief de gebruikte bronnen, verwijzen we naar onze individuele stukken hieronder.
Wat is nepnieuws?
1 Inleiding
“Het verspreiden van foutieve informatie en nepnieuws in het kader van psychologische oorlogsvoering om de vijand te ontmoedigen of als propaganda vóór, tijdens en na gewapende conflicten is van alle tijden”: nepnieuws blijkt niets nieuws te zijn (van der Horst, 2018). Toch is er de laatste jaren steeds meer aandacht voor nepnieuws. Dit heeft onder andere te maken met de verkiezingscampagne van Donald Trump uit 2016, waarin de term veelvuldig werd genoemd en werd gebruikt als retorisch middel. Sindsdien is de term niet meer weg te denken uit de media.
Hoewel nepnieuws geen nieuw fenomeen is, is de snelheid en omvang ervan dit wel: nepnieuws heeft een andere rol gekregen in dit digitale tijdperk. Een onderzoek naar de verspreiding van nepnieuws op Twitter (Allcott & Gentzkow, 2017) heeft aangetoond dat nepnieuws 70% meer kans heeft om geretweet te worden dan legitiem nieuws. Dit is te verklaren vanuit het feit dat vertrouwen in de media en vertrouwen in de wetenschap niet grondig van elkaar verschilt: beide zijn gebaseerd op het scheppen van common ground, een gemeenschappelijke grond waarover wordt gerapporteerd. Mensen zijn geneigd om zich te oriënteren op instanties die hun vertrouwde standpunten in bescherming nemen; over het algemeen houden mensen er immers niet van dat hun wereldbeeld en de rechtvaardiging van hun initiatieven en plannen in vraag worden gesteld. Nepnieuws lijkt beter aan te sluiten bij een onkritische verstandhouding tegenover media. Dit in combinatie met de aantrekkelijkheid van nepnieuws, zowel in de vormgeving als onderwerpkeuze, maakt nepnieuws tot een bedreiging voor de wetenschap.
Ook in de coronacrisis, een actuele crisis ten gevolge van het coronavirus (COVID-19) is er sprake van nepnieuws. Niet alleen worden er dubieuze verhalen gedeeld, er wordt ook foutieve gezondheidsinformatie verspreid rondom de herkenning van symptomen en de bestrijding van het coronavirus. Voorbeelden van dit soort artikelen zijn berichten die bijvoorbeeld stellen dat gorgelen met bleek het coronavirus zou doden of dat huisdieren het virus zouden overdragen (Fuchs, 2020). Als dit soort berichten worden gedeeld, heeft dit logischerwijs een enorme impact op het verloop van de crisis, zo niet een rol in kwesties van leven of dood. Met het oog op de maatschappelijke relevantie van het herkennen van nepnieuws, zal ik in dit literatuuronderzoek beogen een definitie op te stellen van dit complexe fenomeen.
2 Filosofische kwesties
Voordat ik nepnieuws zal proberen te definiëren, zal ik eerst een aantal kwesties bespreken die ten grondslag liggen aan het fenomeen.
2.1 Intentie
Een veel geopperde vraag die ten grondslag ligt aan het definiëren van nepnieuws, is of foutieve informatie daadwerkelijk nepnieuws is, wanneer er geen sprake is van opzet en de foutieve aard van de informatie toe te schrijven is aan een gebrek aan kennis of inzicht. Er wordt dan gekeken naar de intentie achter de rapportage van misinformatie.
Op basis van de verschillende standpunten kan er een smalle definitie en een brede definitie worden opgesteld van nepnieuws, waarin intentie fungeert als onderscheidende factor. De brede definitie stelt dat nepnieuws foutief nieuws is, waar de smalle definitie stelt dat nepnieuws intentioneel en verifieerbaar foutief nieuws is (gepubliceerd door een nieuwszender)(Zhou & Zafarani, 2018)
Over het algemeen wordt onbewuste misinformatie niet bestempeld als nepnieuws en wordt er gekozen voor een smalle definitie van nepnieuws: volgens Berduygina, Vladimirova & Chernyaeva (2019) is dit informatie waarover is gelogen, gemanipuleerde informatie of bewuste vervorming van de informatie. Het nieuws is dan bewust ‘vervuild’ (zie figuur 1 voor het precieze onderscheid tussen intentionele foutieve informatie en onintentionele foutieve informatie).
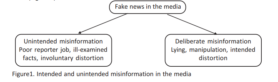
Figuur 1 (Berduygina et al., 2019)
2.2 Waarheid
Hoewel intentionaliteit eventueel te achterhalen is, kan het lastiger zijn om te achterhalen wat ‘waarheid’ precies is. Dit is een vraag waar vele filosofen zich over hebben gebogen. Sommige filosofen veronderstellen dat de waarheid in absolute zin bestaat en dat waarheid ons inherent bekend is, terwijl andere filosofen dit betwijfelen, zo ook Schütz, die stelt: “Omdat de context van een gegeven doorgaans meervoudig is en er in die zin meerdere kaders gelden van waaruit de feitelijkheid van een gegeven kan worden geïnterpreteerd, is elke interpretatie betrekkelijk.” Schütz impliceert hier dat de waarheid in absolute zin niet bestaat. Filosofen zoals Wittgenstein en Goffman sluiten zich bij deze stelling aan, maar ook Kant die stelt dat er geen algemeen criterium voor waarheid kan bestaan buiten de waar-of onwaarheid van predicaatsuitspraken om (Billiet, Opgenhaffen, Pattyn & van Aelst, 2018).
Ervan uitgaande dat er sprake is van absolute waarheid, oppert dit de vraag hoe waarheid van onwaarheid onderscheiden kan worden. Een voor de hand liggend antwoord is het controleren van feiten, maar zelfs feiten zijn onderhevig aan de veronderstellingen van het paradigma waarin ze worden gepresenteerd.
Ik zal mij aansluiten bij de verschillende filosofen die hebben geopperd dat er geen absolute waarheid is. Merk op dat de stelling zichzelf tegenspreekt, dus er kan enkel aangenomen worden dat de absolute waarheid bestaat voor het feit dat er geen absolute waarheid is. Ondanks het feit dat er geen absolute waarheid is, betekent dit niet dat er geen objectieve verslaggeving kan worden gedaan. Hierin speelt onpartijdigheid een belangrijke rol: door een zo betrouwbaar mogelijk beeld te vormen van hoe een gegeven mag en kan worden geïnterpreteerd, kan een objectieve status van nieuws alsnog in zekere zin bereikt worden door nieuwszenders. Hoewel veel nieuwszenders een zekere doelgroep beogen, zou nieuws dat geclassificeerd kan worden als waar, niet alleen binnen het huidige paradigma moeten passen, maar ook universeel toegankelijk moeten zijn.
Met deze informatie in het achterhoofd, is het mogelijk om de begrippen omtrent nepnieuws te bespreken.
3 Definitie
De filosofische kwesties te hebben besproken, kunnen er verschillende aannames worden gedaan over nepnieuws. Aangezien er geen algemeen aangenomen definitie is van nepnieuws, zal ik verschillende definities bespreken zoals die voorkomen in literatuur over dit fenomeen. Bij het classificeren van nepnieuws kan er gekeken worden naar verschillende aspecten, waarvan ik de volgende drie zal behandelen: the degree of falsity., de verschijningsvormen van nepnieuws en mediaplatformen. Ik heb gekozen om deze drie aspecten te behandelen, omdat eventuele andere aspecten zoals ‘afzender’ of ‘doeleinden’ al besproken zullen worden door mijn medeonderzoekers.
The degree of falsity
In het artikel ‘Trends in the spread of fake news in mass media.’ van Berduygina et al. (2019) wordt er gepoogd nepnieuws te definiëren. Om dit te bereiken halen zij een onderzoek aan van Sukhodolov (2017), die nepnieuws classificeert aan de hand van verschillende aspecten: de ratio van ware en valse informatie, de feitelijkheid van het nieuws, de betrouwbaarheid van de betrokken personen, de motieven van nepnieuws en de perceptie van de authenticiteit van het nieuws (zie figuur 2). Samen vormen deze aspecten the degree of falsity, ofwel de mate waarin nieuws nep is. Berduygina et al. zien nepnieuws dus niet als een statisch begrip: het ene nieuws kan nepper zijn dan ander nieuws. Hoeveel kenmerken moeten terugkomen in nieuws om het te bestempelen als nepnieuws, wordt niet vermeld: er is dus niet sprake van een standvastige ondergrens.
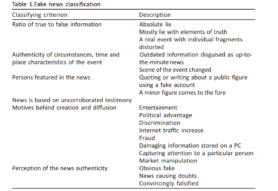
Figuur 2 (Berduygina et al., 2019)
Hoewel er sprake is van weinig consistentie bij een degree of falsity, vormt het wel een nuttige leidraad bij de classificering van nepnieuws. Berduygina et al. (2019) geven bovendien alsnog een sluitende definitie van nepnieuws, namelijk: “fake news is information fabrication or deliberate dissemination of misinformation in social and traditional media with a view to confusing the audience for reaping financial or political gains”. Merk op dat intentie optreedt als onderscheidende factor; nieuws dat als nepnieuws wordt bestempeld is blijkbaar bewust gecreëerd en bovendien vanuit een slechte bedoeling gecreëerd.
Het artikel lijkt zich op het eerste oog misschien tegen te spreken: er wordt een sluitende definitie gegeven van nepnieuws, terwijl nepnieuws geen eenduidige verschijningsvorm kent, maar in verschillende mate voorkomt. Toch sluit het een het ander niet uit: het ene nieuws kan als nepper worden geclassificeerd dan ander nieuws, maar beide kan alsnog de status van nepnieuws worden toegekend.
Verschijningsvormen van nepnieuws
Andere artikelen maken geen expliciet onderscheid in een zekere mate aan nepheid van nieuws, maar benoemen wel dat nepnieuws in verschillende verschijningsvormen kent, waarbij er bij sommige verschijningsvormen grotere consensus heerst over de status van nepnieuws. Zo behandelen Zannettou, Sirivianos, Blackburn & Kourtellis (2019) in het artikel ‘The web of false information: rumors, fake news, hoaxes, clickbait, and various other shenanigans.’ verschillende soorten nieuws die onder nepnieuws geschaard kunnen worden, namelijk:
Fabricated news
Complete fictie; de verhalen zijn niet meer terug te koppelen naar feitelijke informatie, maar volledig verzonnen.
Propaganda
Een subcategorie van fabricated information; complete fictie, waarbij de informatie bedoeld is om specifieke partijen te schaden (vaak gebruikt in een politieke context).
Conspiracy theories
Verhalen die bepaalde situaties of evenementen moeten verklaren door een samenzwering te opperen zonder enig bewijs.
Hoaxes
Nieuws dat feiten bevat die ofwel niet kloppen of onnauwkeurig zijn, maar toch gepresenteerd worden als legitieme feiten.
Biased or one-sided
Verhalen die bevooroordeeld of eenzijdig worden verteld.
Rumors
Verhalen waarvan de waarachtigheid op verschillende manieren kan worden geïnterpreteerd (/ambigu) of nooit is bevestigd.
Clickbait
De bewuste keuze voor misleidende titels en thumbnails (op internet); de titel of thumbnail/cover komt niet overeen met de inhoudelijke informatie en wordt puur gebruikt om de aandacht van het publiek te trekken.
Satire
Verhalen vol ironie en humor; er wordt niet altijd aangegeven dat de gegeven informatie bedoeld is als grap.
Zannetou et al. benadrukken dat er overlap kan optreden: zo kan er bijvoorbeeld bij een satirisch artikel een clickbait-titel voorkomen. Ze zijn van mening dat nepnieuws niet onder één noemer hoeft te worden gebracht en halen daarmee een zeer brede ‘definitie’ aan. Ik zal de genoemde verschijningsvormen als referentiekader gebruiken om de verschijningsvormen van nepnieuws volgens de verschillende artikelen met elkaar te vergelijken.
Uit het artikel ‘Fake news: a survey of research, detection methods, and opportunities’ blijkt dat Zhou & Zafarani (2018) een andere perceptie hebben op welke verschijningsvormen van nieuws als nepnieuws kunnen worden geclassificeerd. Zij maken het volgende onderscheid, weergegeven in figuur 3: kwaadaardig foutief nieuws, foutief nieuws en satire vallen onder nepnieuws, waarbij de categorisering van desinformatie, misinformatie en geruchten onbekend is. De verschijningsvormen van Zannetou et al. die standhouden zijn fabricated news, propaganda, hoaxes, biased or one-sided news, satire en eventueel clickbait.
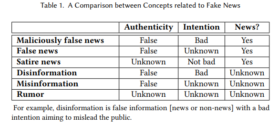
Figuur 3 (Zhou & Zafarani, 2018)
Alcott & Gentzkow zijn in het artikel ‘Social media and fake news in the 2016 election’ opnieuw strenger in de classificatie van nepnieuws. Zij sluiten niet intentionele fouten in de rapportage van nieuws uit, net zoals geruchten, conspiracy theories, satire waarbij er een kleine kans is dat het verhaal wordt aangezien als waarheid, valse verklaringen van politici en verslagen die scheef zijn of misleidend, maar niet per se niet waar, want “fake news is distortion, not filtering”. Deze laatste verschijningsvorm werd niet uitgesloten door Zhou & Zafarani (2018). Alcott & Gentzkow zijn van mening dat de uitgesloten verschijningsvormen van foutief nieuws wel degelijk verband houden met nepnieuws als fenomeen, maar zien deze verschijningsvormen eerder als ‘neefjes’ van nepnieuws dan nepnieuws op zich.
In tabel 1 staat een overzicht van de verschillende verschijningsvormen van nepnieuws volgens de behandelde artikelen. Uit de vergelijking blijkt dat er consensus is over de volgende verschijningsvormen: fabricated news, propaganda (hoewel deze verschijningsvorm onder één noemer zouden kunnen worden geschaard), hoaxes, sommige satire en eventueel clickbait worden gezien als nepnieuws. Deze verschijningsvormen van foutief nieuws kunnen worden gelinkt aan een smalle definitie van nepnieuws, terwijl alle verschijningsvormen van foutief nieuws kunnen worden gelinkt aan een brede definitie van nepnieuws.
Tabel 1
Verschijningsvormen van nepnieuws per artikel.
| Artikel | ||||
| Zannettou et al. | Zhou & Zharafani | Alcott & Gentzkow | ||
| Fabricated news
Propaganda Conspiracy theories Hoaxes Biased or one-sided Rumors Clickbait Satire news |
X
X X X X X X X |
X
X – X X – ? X |
X
X – X – – ? X / – |
|
Mediaplatformen
Verschillende artikelen behandelen niet alleen hoe nepnieuws voorkomt, maar ook waar nepnieuws voorkomt: mediaplatform speelt ook een rol als aspect van de definitie van nepnieuws. Vaak wordt nepnieuws gelinkt aan digitale media en dan specifiek aan sociale media. Dit heeft onder andere te maken met het feit dat sociale media een participatieve onlinecultuur mogelijk maken, waarbij mensen een actieve houding kunnen innemen tegenover nieuws. Zoals benoemd kan nepnieuws sneller verspreid worden dan ooit en dit gebeurt bovendien op een grotere schaal dan ooit tevoren. Nu zorgt zoekgedrag op internet ook vaak voor een tunnelvisie: algoritmen achter een zoekmachine zijn niet neutraal en er is vaak sprake van confirmation bias, wat inhoudt dat mensen geneigd zijn om hun eigen opvattingen te bevestigen. Deze digitale ontwikkelingen maken nepnieuws tot een bedreiging voor de wetenschap, maar ook tot een bedreiging voor de samenleving. Het is dan ook niet gek dat nepnieuws vaak in één adem wordt genoemd met de nieuwste digitale ontwikkelingen.
Hoewel er voornamelijk aandacht is voor nepnieuws in de digitale media, lijkt een digitaal mediaplatform niet te worden beschouwd als een noodzakelijke voorwaarde van nepnieuws. Zannettou et al. (2019) doen zelf geen uitspraken over ‘het’ mediaplatform van nepnieuws, maar halen verschillende studies aan die een multimediale benadering gebruiken in hun onderzoek naar nepnieuws. Dit impliceert dat nepnieuws op verschillende media voorkomt. In het artikel van Berduygina et al. (2019) wordt zowel foutieve informatie verspreid op sociale media als traditionele media bestempeld als nepnieuws: het platform van nepnieuws wordt hier opnieuw niet gezien als een inherent kenmerk van nepnieuws:
Het onderzoek – welke definitie van nepnieuws lijkt bruikbaar?
Voor ons onderzoek naar nepnieuws omtrent het coronavirus, is het handig om de brede definitie te gebruiken qua de verscheidenheid aan verschijningsvormen van nepnieuws. Dit zal meer data opleveren, wat uiteindelijk een betere uitkomst zal bieden aan de hand van een algoritme. Echter, de smalle definitie wordt vaker aangenomen als ‘waar’ en het is net zo goed belangrijk dat nepnieuws verifieerbaar en (eventueel) intentioneel foutief is. Om die reden is het verstandig om een brede definitie aan te nemen, waarbij er geen onderscheid wordt gemaakt in de verschijningsvormen van nepnieuws, aangezien onderzoekers onderling hier toch geen consensus over weten te bereiken. Dit zal een zo breed en realistisch mogelijk beeld geven van de berichtgeving rondom het coronavirus.
4 Conclusie
Voordat de definiëring van nepnieuws behandeld kon worden, is er eerst gekeken naar filosofische kwesties die ten grondslag liggen aan nepnieuws als fenomeen, namelijk: de rol van waarheid en de rol van bewustzijn. Hierbij heb ik aangenomen dat er waarschijnlijk geen absolute waarheid is, maar dat dit niet betekent dat objectieve verslaggeving is uitgesloten. Bovendien speelt intentionaliteit een belangrijke rol bij het onderscheiden van nepnieuws van foutieve informatie; een veronderstelling die terug te vinden is in de besproken artikelen.
De definities van de besproken artikelen bestonden uit verschillende aspecten, waarvan ik drie belangrijke aspecten heb behandeld, namelijk: the degree of falsity, de verschijningsvormen van nepnieuws en mediaplatformen waarop nepnieuws verschijnt.
Uit the degree of falsity is gebleken dat nepnieuws geen eenduidend begrip is. Er is sprake van een verschil in mate aan ‘nepheid’: sommig nieuws kan nepper zijn dan ander nieuws. Dit betekent echter niet dat er geen sluitende definitie van nepnieuws kan worden gegeven.
Uit het analyseren van de verschillende verschijningsvormen van nepnieuws is gebleken dat er een smalle definitie en een brede definitie van nepnieuws kan worden opgesteld.
De smalle definitie is als volgt: “Nepnieuws is het intentioneel produceren of bewust verspreiden van verifieerbaar foutieve informatie.” Deze definitie aangenomen, worden er minder verschijningsvormen van foutief nieuws onder nepnieuws geschaard dan bij de brede definitie, namelijk: fabricated news, propaganda, hoaxes, sommige vormen van satire en eventueel clickbait. Andere verschijningsvormen van foutief nieuws worden dan gezien als gerelateerd aan nepnieuws, maar niet als nepnieuws op zich.
Daartegenover luidt de brede definitie als volgt: “Nepnieuws is foutieve informatie”. Deze definitie aangenomen, worden eigenlijk alle verschijningsvormen van foutieve informatie onder nepnieuws geschaard.
Hoewel nepnieuws bovendien voornamelijk wordt gelinkt aan digitale mediaplatformen zoals sociale media, lijkt dit niet te worden beschouwd als een noodzakelijke voorwaarde van nepnieuws: nepnieuws komt zowel voor op traditionele media als digitale media.
Nepnieuws is een lastig fenomeen om te definiëren, maar aan de hand van de opgestelde definitie en de bijbehorende criteria kan er toch inzicht worden verkregen in dit fenomeen. Dit is niet alleen theoretisch waardevol, maar zal ook van pas komen bij het analyseren van nepnieuws in de praktijk en dan specifiek nepnieuws rondom de coronacrisis. Als nepnieuws onderscheiden kan worden van wetenschappelijk nieuws, kunnen er eventueel levensbedreigende situaties voorkomen worden; grip op de situatie omtrent het coronavirus is gewenst en nu hopelijk makkelijker te bereiken.
5 Bronnen
Van der Horst, H. (2018). Nepnieuws. Een wereld van desinformatie. Schiedam: Scriptum.
Allcott, H ., & Gentzkow, M. (2017). Social media and fake news in the 2016 election. Journal of economic perspectives, 31(2), 211-236.
Fuchs, C. (2020). Everyday life and everyday communication in coronavirus capitalism. TripleC: communication, capitalism & critique, 18(1), 375-399.
Zhou, X. & Zafarani, R. (2018). Fake news: a survey of research, detection methods and opportunities. arXiv:1812.00315.
Berduygina, O., Vladimirova, T. & Chernyaeva, E. (2019). Trends in the spread of fake news in mass media. Media Watch, 10(1), 122-132.
Billiet, J., Opgenhaffen, M., Pattyn, B. & van Aelst, P. (2018). De strijd om de waarheid. Over nepnieuws en desinformatie in de digitale mediawereld. Brussel: KVAB Press.
Sukhodolov, A.P. (2017). The phenomenon of “fake news” in the modern media space. Euro-Asian cooperation: humanitarian aspects, 1, 87-106.
Zannettou, S., Sirivianos, M., Blackburn, J. & Kourtellis, N. (2019). The web of false information: rumors, fake news, hoaxes, clickbait, and various other shenanigans. Journal of data and information quality, 11(3), 1-26.
Wie verspreiden nepnieuws en waarom?
1 Inleiding
Met de komst van het internet en de ontwikkeling van sociale platformen, zoals Facebook, Whatsapp en Twitter, is de verspreiding van nieuws makkelijker dan ooit tevoren. Het gemak waarmee het verspreiden van nieuws gepaard gaat, geldt onvermijdelijk ook voor het verspreiden van ‘’nepnieuws’’.[1] Onder nepnieuws verstaan we ‘’nieuws dat niet op waarheid berust en vaak bewust wordt verspreid om de publieke opinie te beïnvloeden.’’ [2] Nepnieuws is geen nieuw begrip in onze samenleving, maar wel een begrip dat de afgelopen jaren is gegroeid in omvang door de opkomst van sociale platformen. [3]
Sociale platformen bieden de ideale omgeving voor het plaatsen en het verspreiden van (nep)nieuws, aangezien via die weg een zeer groot scala aan mensen kan worden bereikt. Gebruikers van sociale platformen zijn gemakkelijk in staat om dergelijke ‘’neppe’’ berichten te lezen en deze vervolgens bewust of onbewust te liken en/of te delen. De verspreiding van nepnieuws op grote schaal, kan de samenleving op zorgwekkende manieren treffen.[4] Daarom is het noodzakelijk dat de verspreiders van nepnieuws en hun bijbehorende motieven duidelijk in kaart worden gebracht, zodat de verspreiding van nepnieuws tegen kan worden gegaan.
Uit deze gedachtegang volgt de onderzoeksvraag die in dit literatuuronderzoek centraal staat: ‘’Wie verspreiden er nepnieuws en wat zijn de motieven hierachter?’’
Om een antwoord te geven op deze vraag, zal er in dit onderzoek een onderscheid worden gemaakt tussen twee groepen die nepnieuws de wereld inbrengen. De eerste groep bestaat uit software gestuurde programma´s en de tweede groep bestaat uit mensen als individu en als lid van een organisatie. Aan de hand van verschillende onderzoeken zal er dieper worden ingegaan op deze specifieke groepen en hun motieven.
2 Sociale bots
Een ‘’social bot’’, oftewel sociale bot, is een computeralgoritme dat automatisch inhoud produceert en interactie heeft met mensen op sociale media, in een poging hun gedrag na te bootsen en mogelijk te veranderen.[5] Social bots worden sinds de komst van sociale platformen in grote hoeveelheid op het internet geproduceerd, mede vanwege de lage kosten waarmee de productie gepaard gaat. [6] Er valt een onderscheid te maken tussen twee soorten social bots. Enerzijds heb je de ‘’goedaardige bots’’, die meestal onschadelijk en zelfs nuttig zijn. Deze bots voegen de inhoud van verschillende bronnen, zoals nieuwspagina’s, bij elkaar tot een geheel. Anderzijds heb je de ‘’kwaadaardige bots’’, die schade toebrengen aan de feitelijkheid waarmee nieuws gepaard zou moeten gaan. Deze bots misleiden, exploiteren en manipuleren het discours van sociale media met berichten in de vorm van geruchten, spam, smaad en ruis.[7] Het enige motief van deze kwaadaardige bots om nepnieuws te verspreiden, is het creëren van sociale wanorde.[8]
3 Strategieën
Deze laatste vorm van social bots, de kwaadaardige bots, spelen een grote rol bij het creëren en het verspreiden van nepnieuws. De reden dat veel gebruikers van sociale platformen de berichten van social bots aannemen als de waarheid, heeft te maken met de manipulatiestrategieën waarvan deze bots gebruik maken.[9] Ten eerste zijn bots steeds beter in staat om menselijke eigenschappen aan te nemen, waardoor ze vaak moeilijk te onderscheiden zijn van echte profielen. Zo zijn social bots tegenwoordig in staat om deel te nemen aan complexere vormen van interacties, zoals het onderhouden van gesprekken met andere mensen en het beantwoorden van vragen. Ook zijn ze in staat om te infiltreren in online discussies en daar zelf informatie aan toe te voegen via online research.[10] Dit is ook het geval bij discussies rondom het zeer actuele COVID-19, een besmettelijke ziekte die wordt veroorzaakt door een nieuw coronavirus. Hierover plaatsen bots massaal berichten en foto´s van lege supermarken en delen ze daarnaast op grote schaal neppe, beangstigende twitterberichten.[11]
Een tweede manipulatiestrategie van bots, is om zich te focussen op makkelijk beïnvloedbare mensen. Bots proberen meer invloed te verkrijgen door nieuwe volgers te verzamelen en hun sociale kringen uit te breiden. Ze kunnen op het sociale netwerk zoeken naar een specifieke groep mensen waarvan ze de aandacht willen trekken. [12] De menselijke kant van bots is hier zeer verraderlijk, aangezien mensen de neiging hebben om sociale contacten te vertrouwen. Zodoende kunnen hele groepen aan mensen worden gemanipuleerd om op deze manier geproduceerde inhoud te geloven en te verspreiden. Ten slotte zijn bots in staat om hun geografische locatie te verbergen.[13] Hierdoor is het lastig om te achterhalen wie bepaalde bots op de wereld heeft gezet. Deze manipulatiestrategieën zorgen ervoor dat bots makkelijk in staat zijn om nepnieuws te verspreiden, waarbij het zeer lastig is om te achterhalen dat het bots zijn, in plaats van mensen.
4 Individuen en organisaties
Naast social bots, wordt nepnieuws ook rechtstreeks door mensen de wereld in gebracht via sociale platformen, zoals Facebook en Twitter. Zowel specifieke individuen als groepen en organisaties kunnen baat hebben bij het verspreiden van nepnieuws. Deze groepen zijn van elkaar te onderscheiden aan de hand van hun motieven. De meest voorkomende motieven zijn politiek, financieel of sociaal van aard. Iemand die nepnieuws verspreidt vanuit een politiek motief, doet dit om politieke verwarring te veroorzaken en probeert zodoende de publieke perceptie te beïnvloeden over specifieke kwesties en individuen. Als er sprake is van een sociaal motief, brengt iemand nepnieuws de wereld in met als doel zijn/haar sociale behoeften tegemoet te komen, zoals diens status, identiteitsopbouw en de mate van aandacht en entertainment. Indien iemand desinformatie verspreidt vanuit een financieel motief, doet hij/zij dit om daar financieel van te groeien.[14] Aan de hand van deze drie motieven zullen de verschillende menselijke actoren worden behandeld die nepnieuws verspreiden.
5 Politieke organisaties
Politieke organisaties zijn organisaties die zich bezighouden met politieke activiteiten, zoals lobbyen en adverteren voor campagnes. Politieke organisaties zijn gericht op het bereiken van duidelijk gedefinieerde politieke doelen, die doorgaans de belangen van hun leden ten goede komen. [15] Verschillende politieke organisaties dragen bij aan het verspreiden van nepnieuws vanuit politieke motieven. Zo delen ze desinformatie om hun organisatie te promoten, andere concurrerende organisaties in een slecht daglicht te zetten of een specifiek verhaal naar het publiek te brengen. Deze politieke desinformatie wordt vaak aangeduid met het begrip propaganda, ‘’the deliberate, systemic attempt to shape perceptions, manipulate cognitions, and direct behaviour to achieve a response that furthers the desired intent of the propagandist” (Jowett & O’Donnell, 2012, p. 7). [16] Dit soort politiek-gerelateerd nepnieuws heeft een intensiever effect op sociale platformen in vergelijking met andere soorten nepnieuws en vooral rond de tijd van verkiezingen valt er niet aan te ontkomen. Zo speelde de verspreiding van nepnieuws door politieke organisaties ook een zeer grote rol tijdens de Amerikaanse verkiezingen van 2016. Er werden veel nep berichten op Facebook geplaatst die in het voordeel werkten van Trump. Hierdoor wordt er ook wel gezegd dat Trump nooit president was geworden, als nepnieuws niet zo´n grote invloed had gehad. [17]
6 Overheden
Naast politieke organisaties, komt het ook voor dat mensen uit de overheid zich vanuit politieke motieven inzetten om nepnieuws te verspreiden. De overheid beschikt over zogenaamde government‐based cyber troops die de publieke opinie moeten beïnvloeden. Deze personen zijn rechtstreeks in dienst van de staat als ambtenaar en vormen vaak een klein onderdeel van een groter overheidssysteem. Vooral in China is het openbaar bestuur achter de activiteiten van cybertroepen ongelooflijk groot: lokale kantoren werken daar samen met hun regionale en nationale tegenhangers om uit meerdere gebeurtenissen een gemeenschappelijk verhaal te creëren en te verspreiden.[18] Daarnaast zijn er ook berichten over andere buitenlandse regeringen die valse informatie over andere landen delen om de publieke opinie te manipuleren. Zo gebeurde dit ook hoogstwaarschijnlijk door de Russische regering bij de Amerikaanse verkiezingen van 2016. Vermoedelijk gebruikten Russische operators die voor de Russische overheid werkten destijds Twitter en Facebook om anti-Clinton berichten te verspreiden.[19]
7 Journalisten
Journalisten spelen een cruciale rol, dan wel de belangrijkste rol, bij de verspreiding van nieuws. Ze verzamelen gegevens en verspreiden dit vervolgens in de vorm van een nieuwsbericht naar de buitenwereld. Bij dit proces hebben ze de grote verantwoordelijkheid om de juiste informatie te publiceren, aangezien misinformatie grote gevolgen kan hebben. Ondanks deze gevolgen, zijn er toch journalisten die onbewust of bewust nepnieuws verspreiden. Als een journalist er bewust voor kiest om niet de algehele waarheid naar buiten te brengen, wordt dit aangeduid met riooljournalistiek, de leugenachtige, belasterende vorm van journalistiek, bestaande uit een samenraapsel van roddels, ongefundeerde beweringen en halve waarheden.[20] Het motief achter riooljournalistiek is financieel, aangezien ze met hun berichtgeving de verkoopcijfers van hun blad willen bevorderen. Er zijn ook journalisten die sociale motieven hebben om nepnieuws te schrijven en te verspreiden. Zo willen ze opvallen en op die manier de populariteit van hun platform, site of krant te vergroten. [21]
8 Trollen
‘’Trolls’’, oftewel trollen, komen in grote mate voor op sociale platformen en zijn een grote bron achter de verspreiding van nepnieuws. Trollen zijn gebruikers van sociale platformen die bewust provocerende- of niet-relevante berichten plaatsen om andere gebruikers uit te lokken of emotionele druk uit te oefenen. Op deze wijze beïnvloeden ze de discussiestroom van een website.[22] De meeste trollen plaatsen nepnieuws vanuit een sociaal motief, aangezien ze puur en alleen chaos schoppen voor hun eigen persoonlijke plezier.[23] Daarnaast is er een groep trollen die vanuit bepaalde instanties wordt betaald om invloed uit te oefenen op de mening van gebruikers. In dit geval is er sprake van een financieel motief, aangezien deze trollen puur dit gedrag vertonen om er geld aan te verdienen. De platformen waar trollen vooral hun zaadjes planten, zijn Reddit en 4chan. Reddit is een platform waar het aantal omhoog- en omlaag stemmen van een bericht de populariteit en de volgorde bepaalt waarin het bericht op het platform verschijnt. 4chan is een anonieme gemeenschap waar alle berichten na een week worden verwijderd.[24] Zowel Reddit als 4chan vormen dus de perfecte omgeving voor trollen, omdat ze geen grenzen hebben bij het schrijven en lastig te achterhalen zijn.
9 Useful idiots
‘’Useful idiots’’, oftewel nuttige idioten, zijn gebruikers die valse informatie delen, voornamelijk omdat ze worden gemanipuleerd door de leiders van een organisatie of omdat ze naïef zijn. Meestal zijn nuttige idioten normale gebruikers die niet volledig op de hoogte zijn van de doelen van de organisatie, daarom is het uiterst moeilijk om ze te identificeren. [25] Deze mensen lezen bijvoorbeeld een bericht op Facebook wat is geplaatst door een ‘’troll-account’’ en nemen dit vervolgens direct aan als de waarheid door het bericht te liken of te delen. In deze situaties dragen useful idiots dus bij aan de verspreiding van nepnieuws, puur vanwege hun onwetendheid en naïviteit.
10 Conclusie
Concluderend kan er gesteld worden dat nepnieuws door zowel software gestuurde programma´s kan worden verspreid, als door menselijke organisaties en individuen. Software gestuurde programma´s, oftewel social bots, hebben als doel om sociale wanorde te creëren. Dit doen ze door zeer gericht misleidende en manipulatieve berichten te plaatsen op sociale platformen, in de hoop gebruikers te beïnvloeden. De menselijke actoren die nepnieuws verspreiden zijn politieke organisaties, overheden, journalisten, trollen en useful idiots. Zij verspreiden nepnieuws vanuit drie mogelijke motieven. Deze motieven kunnen politiek, financieel en sociaal van aard zijn en hebben als gemeenschappelijke factor dat ze de verspreiding van nepnieuws als einddoel hebben. Nu er meer duidelijkheid is over de verspreiders van nepnieuws en hun motieven, kan er eerder een oplossing worden gevonden om de verspreiding van nepnieuws tegen te gaan. Voor een vervolgonderzoek zou het interessant zijn om te kijken naar mogelijke oplossingen of technieken die zouden kunnen bijdragen aan de opsporing van deze nepnieuwsverspreiders.
[1] Redactie Volkskrant. ‘’Nepnieuws produceren en verspreiden is makkelijker dan ooit: hulpmiddelen liggen voor het oprapen’’
[2] Van Dale. ‘’Betekenis ‘nepnieuws’’’
[3] Redactie Volkskrant. ‘’Nepnieuws produceren en verspreiden is makkelijker dan ooit: hulpmiddelen liggen voor het oprapen’’
[4] S. Zannettou et al. ‘’The Web of False Information: Rumors, Fake News, Hoaxes, Clickbait, and Various Other Shenanigans’’
[5] E. Ferrara et al. ‘’The Rise of Social Bots’’
[6] C. Shao et al. ‘’ The spread of fake news by social bots’’
[7] E. Ferrara et al. ‘’The Rise of Social Bots’’
[8] R. Ko. ‘’ Social Media Is Full of Bots Spreading COVID-19 Anxiety. Don’t Fall For It’’
[9] C. Shao et al. ‘’ The spread of fake news by social bots’’
[10] E. Ferrara et al. ‘’The Rise of Social Bots’’
[11] R. Ko. ‘’ Social Media Is Full of Bots Spreading COVID-19 Anxiety. Don’t Fall For It’’
[12] E. Ferrara et al. ‘’The Rise of Social Bots’’
[13] C. Shao et al. ‘’ The spread of fake news by social bots’’
[14] B. Kalsnes. ‘’Fake news’’
[15] B. Kalsnes. ‘’Fake news’’
[16] B. Kalsnes. ‘’Fake news’’
[17] H. Allcott & M. Gentzkow. ‘’ Social Media and Fake News in the 2016 Election’’
[18] S. Bradshaw & P. Howard. ‘’Troops, Trolls and Troublemakers: A Global Inventory of Organized Social Media Manipulation’’
[19] S. Shane. ‘’The Fake Americans Russia Created to Influence the Election’’
[20] Nederlandse Encyclopedie. ‘’Betekenis ‘riooljournalistiek’’’
[21] S. Zannettou et al. ‘’The Web of False Information: Rumors, Fake News, Hoaxes, Clickbait, and Various Other Shenanigans’’
[22] S. Zannettou et al. ‘’The Web of False Information: Rumors, Fake News, Hoaxes, Clickbait, and Various Other Shenanigans’’
[23] E. Buckels et al. ‘’Trolls just want to have fun’’
[24] S. Zannettou et al. ‘’Disinformation Warfare: Understanding State-Sponsored Trolls on Twitter and Their Influence on the Web’’
[25] S. Zannettou et al. ‘’The Web of False Information: Rumors, Fake News, Hoaxes, Clickbait, and Various Other Shenanigans’’
De verspreiding van misinformatie door OSN’s
1 Inleiding
Voor het honours research seminar zullen we in deel II van de cursus proberen te achterhalen hoe nepnieuws herkent kan worden. Hiervoor willen we enkele berichten analyseren en vervolgens een algoritme trainen dat deze en andere nepnieuws berichten kan herkennen. In dit stuk zijn we de literatuur ingedoken om te ontdekken hoe nepnieuws zich verspreidt over sociale media. Eerst komt er wat achtergrond en context. Vervolgens zullen we de vraag beantwoorden en tot slot geef ik een advies voor de rest van het onderzoek.
2 Achtergrond
Nepnieuws of misinformatie kennen we eigenlijk al heel lang. Zo komt het al eeuwen in de vorm van spotprenten of propaganda. Machthebbers van vroeger hadden liever niet dat hun volk een slecht beeld over hen kreeg of goed nieuws ontving over hun tegenstanders. Dit geldt echter niet alleen voor de machthebbers, ook uitgevers van nieuws kunnen zelf hun vooroordelen in het nieuws terug laten komen.
Vorige eeuw nog was er een groep mensen die de macht had om een belangrijk nieuwsmedium te censureren. Redacteuren van kranten kunnen ervoor kiezen om een artikel die hun eigen land in een goed daglicht zet een prominentere plek te geven dan een artikel dat negatief is over hun land. Bovendien kan er ook voor gekozen worden een artikel helemaal niet te plaatsen.
Deze vorm van censuur kwam niet vaak voor, maar was ook niet ongekend. Zo is er een geval bekend van het amerikaanse Times Magazine waar een redacteur een artikel over communisme in de Spaanse Staat[1] weigerde omdat het “communisme in een te goed daglicht” zou zetten. (Gans H. , 1979) Soms blijft het onduidelijk of de censuur van redacteuren intentioneel is. Woordkeuze in artikelen is belangrijk, maar soms zijn er geen neutrale worden beschikbaar. Zoals over de jonge amerikaanse mannen die niet in de Vietnamoorlog wilden vechten; ‘De media had ze ontwijkers, vermijders of verzetters kunnen noemen.’ [2] Hierbij zetten de eerste twee termen de mannen in een kwaad daglicht en de laatste term zet de mannen in een goed daglicht. De woordkeuze hier is van groot belang voor het beeld dat de lezer van de mannen krijgt.
3 Misinformatie en OSN’s
Vandaag de dag hebben we minder met deze problemen te maken. We maken massaal gebruik van online sociale netwerken (OSN’s) waarbij er niet één of een kleine groep redacteuren aan de top staat die bepaald wat gepubliceerd mag worden en hoe het gepubliceerd mag worden. Toch is misinformatie nog steeds een probleem. Door de verandering van het medium ‘gedraagt’ misinformatie zich anders. Iedereen is een potentiële bron én is een onderdeel van de verspreiding ervan. Zoals Charley heeft uitgelegd zijn useful idiots en trollen normale gebruikers die bewust of onbewust nepnieuws verspreiden. Echter zullen we zien dat niet iedereen even belangrijk is voor de verspreiding van die nepnieuws.
Door OSN’s kan misinformatie omtrent covid-19 (het coronavirus) vrijspel krijgen om zich snel te verspreiden. Om dit tegen te gaan kunnen we uitzoeken hoe informatie zich online verplaatst. Als we weten hoe misinformatie zich verspreidt, kunnen we deze inzichten gebruiken om ervoor te zorgen dat de juiste informatie zich over een OSN verspreid voordat de misinformatie dat doet.[3] Ook is misinformatie met een hoge nauwkeurigheid te herkennen aan de manier waarop het zich verspreid. (Castillo, Mendoza, & Poblete, 2011) In tijden waarin nepnieuws zich sneller verspreidt dan het virus is het belangrijk om te weten hoe misinformatie zich verspreidt door en tussen OSN’s. We willen weten wat de gevaren zijn en wat de grote partijen zoals de OSN-platformen en overheden en wij als studenten kunnen doen om nepnieuws effectief tegen te gaan. Deze vragen zullen in dit deel van het literatuuronderzoek worden beantwoord.
4 Het gevaar van nepnieuws in medische context
Terugkijkend naar voorgaande epidemieën zijn er een paar dingen die terugkomen. Voor HIV/AIDS, Ebola en de varkensgriep ging er misinformatie rond. Er gingen verhalen rond dat ze niet echt waren, of gemaakt waren door een overheid of de elite om een bepaald deel van de bevolking te verzwakken of uit te roeien. (Mian & Khan, 2020) (Stern, 2014)
In 2014 heeft dit ervoor gezorgd dat er in Guinee onverwachts een tweede golf aan Ebola patiënten kwam. De bewoners van het platteland vertrouwde de buitenlandse hulpverleners niet. Er deden geruchten de ronde dat ‘de rebellen in de gele pakken’[4] (Figuur 1) er niet waren om te helpen, maar juist de oorzaak van de vele slachtoffers waren. Dit had tot gevolg dat de bewoners op het platteland zich niet meer meldden als Ebola-patiënt. Toen er drie weken[5] later er zich geen nieuwe patiënten meer hadden gemeld, zagen de hulporganisaties dit als hét teken dat de uitbraak voorbij was en de hulporganisaties begonnen hun aanwezigheid af te bouwen. Niet veel later werden de artsen overspoeld door nieuwe patiënten.
Uit wantrouwen hadden deze nieuwe patiënten zich niet eerder gemeld. Ondertussen hadden ze helaas wel andere landgenoten besmet. Als gevolg steeg het aantal bevestigde nieuwe ebolagevallen in een maand tijd naar 290 om vervolgens bijna een jaar later een nieuwe piek te bereiken op 1120 patiënten. Dit terwijl de oude piek op slechts 120 patiënten lag. (US Centers for Disease Control and Prevention, 2019) Het is niet ondenkbaar dat de Ebola uitbraak minder dodelijk geweest zou zijn indien deze mensen beschikking hadden over de juiste informatie.
Ook over het coronavirus gaan er nu vergelijkbare verhalen rond. Het zou bijvoorbeeld gemaakt zijn in een lab als wapen, of het virus bestaat niet eens en is een verzinsel van een overheid om het volk in bedwang te houden. (Mian & Khan, 2020) Minder sensationeel maar wellicht wel schadelijker zijn de verhalen over curen voor het virus. Zo ging er zonder bewijs rond dat vitamine C, het eten van knoflook en een chloordioxide oplossing de verspreiding van het virus zouden kunnen tegen gaan. (Mian & Khan, 2020) Naast dat deze theorieën mensen een onterecht gevoel van veiligheid geven, kan het ook gevaarlijk zijn voor individuen die deze theorieën geloven. Het laatste type gerucht heeft zeker een dode teweeg gebracht. (The Guardian, 2020)
Omdat een groot deel van de misinformatie over het coronavirus zich online verspreidt willen we graag in beeld brengen hoe dit gebeurt. Waar komt deze informatie vandaan en hoe kan het gestopt worden? Hiervoor zullen we kijken naar misinformatie op online social networks (OSN’s) en enkele onderzoeken die de verspreiding van (mis)informatie op deze netwerken beschrijft.

Figuur 1: de gele pakken van hulpverleners in Guinee tijdens de Ebola uitbraak.
Bron: Dominique Faget/AFP
5 Misinformatie op OSN’s
Online vormen mensen (gebruikers) knopen in een groot netwerk dat zich huisvest op verschillende OSN’s (de platformen) en losse webpagina’s. Misinformatie bevat vaker weblinks of URL’s die verwijzen naar deze pagina’s dan andere berichten. (Resende, et al., 2019) Hoe informatie zich online verspreidt, kan worden beschreven aan de hand van twee wetmatigheden. De power law omschrijft hoe hoe het komt dat informatie van sommige pagina’s, blogs en forums wel wordt opgepikt en gedeelt en andere niet. Assimilatie beschrijft hoe vooroordelen informatie kan veranderen in misinformatie wanneer het vaak gedeelt wordt.
6 Power law: niet elke bron van misinformatie is gelijk
Het world wide web (WWW) is niet een uniform verdeeld netwerk. Op het internet blijven gebruikers, binnen het WWW, vaak binnen eigen subnetwerk wat een echokamer kan vormen. Dit komt doordat pagina’s geneigd zijn om soortgelijke pagina’s te linken. Dit wordt preferential attachment genoemd en wordt omschreven door de power law.
Pagina’s met veel binnengaande verbindingen (weblinks) hebben volgens de power law een grotere kans om nieuwe weblinks te krijgen dan pagina’s die nauwelijks binnengaande verbindingen hebben. Goed verbonden pagina’s zullen zo steeds beter verbonden worden. Een nieuwe pagina zal waarschijnlijker linken naar ‘facebook.com/’, wat goed gelinkt is door de like-knop die op veel websites te vinden is, dan naar ‘ditjesendatjes.nl/puzzel/’ waar minder weblinks naar toe wijzen. De kans dat een nieuwe pagina A een weblink naar pagina B maakt is, volgens deze wetmatigheid, dus afhankelijk van hoeveel weblinks er al naar pagina B zijn. (Faloutsos, Faloutos, & Faloutsos, 1999) Hierdoor is er slechts een klein aantal goed gelinkte pagina’s die invloed hebben op de informatie op alle pagina’s.
Deze versie van de power law gaat er impliciet vanuit dat de makers van de pagina’s een geheel beeld hebben van het internet. Dit is echter erg onwaarschijnlijk. Het is niet alsof de maker van een pagina het hele internet afgaat om te zien waar de meeste weblinks naar toe wijzen om vervolgens naar de meest voorkomende pagina een weblink te maken en zijn informatie hiervan over te nemen. Die makers van de pagina’s zijn voor een belangrijk deel (direct of indirect) mensen[6]. Vandaag de dag zijn de gebruikers van het web, ook de makers van de inhoud van de pagina’s. Deze gebruikers hebben niet een compleet beeld van het internet en zullen hun keuze om pagina B of C te linken niet laten afhangen van het hele internet.
Wat wel terug te zien is ‘soort zoekt soort-achtige’ omstandigheden. Pagina’s hebben een grotere kans om weblinks te maken die verwijzen naar pagina’s die over hetzelfde onderwerp gaan. (Mossa, Barthélémy, Stanley, & Nunes Amaral, 2002) Zo zal een pagina over fietsbanden sneller een weblink maken naar een pagina over verschillende soorten ventielen dan over verschillende soorten roofvogels. Bezoekers van deze pagina zullen vanzelfsprekend eerder de pagina over ventielen bezoeken dan die over roofvogels. Als we spreken over fietsbanden, ventielen en roofvogels dan maakt dat niet zoveel uit. Als we echter over ‘healthy lifestyle tips van Sanne’ hebben, dan is het minder fijn dat deze paginabezoekers naar ‘Voorkom het Coronavirus met deze vijf maaltijden’ stuurt in plaats van ‘informatie over het coronavirus: symptomen en hoe was je goed je handen’.
Wetenschappelijke bladen verwijzen vooral naar populaire wetenschappelijke bladen en persoonlijke blogs vooral naar populaire persoonlijke blogs. Doordat bezoekers met de ene interesse niet gauw een pagina zouden opzoeken met nuttige informatie die niet in hun niche past, zullen ze naar die informatie geleid moeten worden via die niches, maar die niches linken vooral naar zichzelf. Hierdoor wordt het echokamereffect jaar op jaar groter. De pagina’s nemen informatie van de grote pagina’s in hun niche over en in sommige gevallen helaas zonder controle.
Wanneer OSN’s hierbij worden betrokken kan een false fact echt viraal gaan. Zoals Charley eerder beschreef spelen bots en trolls een belangrijke rol in het verspreiden van onwaarheden. Bots kunnen binnen echokamers snel korte emotionele berichten doen rondgaan. De gebruikers die al in deze niche zitten hebben weinig informatie nodig over berichten die in een lijn staat met hun interesses. Wanneer ze een bericht zien wat overeenkomt met hun wereldbeeld zullen ze het al snel geloven en delen. Trolls spelen juist een belangrijke rol in het overtuigen van mensen buiten deze niches. Gebruikers buiten een echokamer hebben vaak meer informatie nodig om hun berichten als waar aannemen. (Andrews, 2019) Menselijke trollen kunnen deze extra informatie geven.
Bovendien geldt de power law ook voor gebruikers in sociale netwerken. Er is slechts een klein aantal gebruikers die de bron is van de meest gedeelde misinformatie. (Andrews, 2019)[7] Deze kleine groep gebruikers bepaald het ‘succes’ van een nepnieuws bericht. Vaak zijn dit de mensen met veel (online) aanzien en volgers. Gebruikers die in hetzelfde subnetwerk zitten zullen sneller een bericht delen van een van deze invloedrijke verspreiders dan van een willekeurige ander iemand in hetzelfde subnetwerk. Het maakt hierbij niet uit of deze gebruikers zelf deze invloedrijke mensen volgen of niet. Als zij en hun volgers dezelfde interesse hebben dan is de kans groot dat het bericht hen bereikt.
7 Assimilatie: berichten kunnen veranderen
Wat niet vergeten mag worden is dat niet elke bericht met misinformatie ter wereld komt als onwaar. Informatie kan een OSN als correcte informatie binnen komen en na aantal keren delen zijn veranderd in misinformatie. Dit kan komen door assimilatie. Dat is hetzelfde fenomeen dat ervoor zorgt dat roddels uit de hand lopen en in het doorfluisterspel[8] het uiteindelijke verhaal niet overeenkomt met het oorspronkelijke verhaal. Dat blijkt ook uit een roddel experiment van (Allport & Postman, 1947) daaruit bleek dat uit de helft van chains aan mensen het oorspronkelijke verhaal aangepast werd.
Door (Silverstein, 1987) wordt vermoed dat dit ook een rol speelt in het verspreiden van misinformatie. Mensen vullen de gaten van het verhaal in met wat volgens hun wereldbeeld het beste past. Soms wordt er iets toegevoegd aan een verhaal, soms wordt er iets weggelaten of veranderd. Na een aantal keer dit proces door te zijn gegaan kan een bericht totaal veranderd zijn. Met name op messenger-OSN’s zoals Telegram, Signal en Whatsapp is dit een probleem. Zo hebben (Resende, et al., 2019) in hun onderzoek naar misinformatie in WhatsAppgroepen rekening moeten houden met assimilatie. Om de verspreiding van nepnieuws bij te houden beschouwde ze berichten die erg op elkaar leken als hetzelfde bericht[9]. Later volgt meer over dat onderzoek.
Door de power law weten we dat pagina’s geneigd zijn om informatie over te nemen en dat gebruikers sneller informatie delen die al populair is in de eigen (online) gemeenschap. Dit heeft tot gevolg dat informatie die binnen een gemeenschap als ‘waar’ wordt beschouwd sneller en vaker wordt gedeelt dan informatie van buiten de eigen gemeenschap. Bovendien zijn slechts een paar van de gebruikers in het netwerk verantwoordelijk voor het grootste deel van de misinformatie.
Ook weten we dat door assimilatie deze vaak gedeelde informatie kan veranderen. Zo kan een bericht met echt nieuws na propagatie veranderen in een bericht met nepnieuws. Pas als dit bericht een van de invloedrijke mensen in een gemeenschap bereikt en door hen gedeelt wordt krijgt deze pas echt voet aan de grond . Dit is ook terug te zien in de resultaten van de volgende twee onderzoeken naar misinformatie op Facebook en WhatsApp.
8 Verschillen en overeenkomsten in informatie en misinformatie in OSN’s
Uit het onderzoek van (Del Vicario, et al., 2016) dat keek naar de verspreiding van nepnieuws op Facebook. Komen een paar overeenkomsten en verschillen tussen misinformatie en correcte informatie naar voren. Dit onderzoek vergeleek drie categoriën van berichten gedeelt op facebook; ‘wetenschapsnieuws’, ‘conspiracynieuws’ en ‘satire en trollen’. Hierbij wordt alleen conspiracy-nieuws als misinformatie gezien.
Deel-curve
Op Facebook volgt zowel misinformatie als wetenschapsnieuws het zelfde patroon. Gedurende de lifetime van een bericht (de tijd tussen de eerste keer dat een bericht gedeelt wordt en de laatste keer dat een bericht gedeelt wordt) zijn er twee pieken in activiteit. In het begin is er een snelle toename in activiteit tot de eerste hoge piek en na ongeveer 20 uur is er een tweede kleinere piek. (figuur 2) Ongeacht de waarheid van een bericht volgt hij dezelfde curve in het aantal maal dat deze gedeelt wordt.
Voor beide categorieën geldt dat de meeste berichten in de categorie een korte lifetime hadden slechts 26,82% van het wetenschapsnieuws en 17,79% van de conspiracies hadden een lifetime van langer dan een dag. Een vergelijkbaar deel van zowel het wetenschapsnieuws als de conspiracies verdwijnt zelfs binnen twee uur. Dit is beide terug te zien door de sterke daling na de eerste piek (na 2 uur) en de tweede piek (na ongeveer 20+ uur).
Interesse
Uit hetzelfde onderzoek kwam nog een verschil tussen deze twee groepen berichten naar voren. Bij berichten in de categorie ‘conspiracy’ bleek er een positief verband tussen de interesse[10] in het bericht en de lifetime van een bericht. Berichten die erg populair waren werden dus langer gedeelt. Bij berichten in de categorie ‘wetenschapsnieuws’ was dit verband er echter niet. Berichten waar veel interesse in was werden minder lang gedeelt dan berichten waar minder interesse in was.(figuur 3) Bij wetenschapsnieuws werden berichten waar relatief weinig interesse in werd getoond het langste gedeelt. Iets minder interesse en de lifetime is minder, meer interesse en de lifetime is meer uiteenlopend.
Figuur 3 De lifetime van conspiracy- (links) en wetenschapsnieuwsberichten (rechts) uitgezet tegenover hun cascade size. bron: https://www.pnas.org/content/113/3/554
homogeniteit
Verder werd er ook gekeken naar homogeniteit van de delers van de berichten. Dit is groter wanneer meer connecties van een gebruiker dat het bericht deelt, dit bericht ook deelt. Hoewel beide categorieën van berichten vrij homogeen waren was dit voor conspiracy meer dan voor wetenschapsnieuws. (figuur 4) Dit kan erop wijzen dat gebruikers die conspiracies delen meer in een echokamer zitten dan gebruikers die wetenschapsnieuws delen.
De onderzoekers leggen uit dat de kwaliteit van de gedeelde informatie daalt bij hogere een homogeniteit. Dit komt doordat de gebruikers in deze groepen grotendeels dezelfde interesses delen. Er is dan minder feedback van gebruikers met een ander wereldbeeld. Dit werkt terugkoppeling in de hand en laat de mogelijkheid tot confirmation biases groeien. Dit heeft polarisatie en wantrouwen tot gevolgen.
Een andere groep onderzoekers (Resende, et al., 2019) keken naar tekstberichten die gedeelt werden op de messenger-app WhatsApp. Dit OSN verschilt van facebook in het feit dat whatsapp gericht is op een-op-een conversaties of groepsgesprekken terwijl facebook voor een groot deel openbaar is. De onderzoekers hebben in WhatsAppgroepen alle tekstberichten verzameld en deze gecategoriseerd in ‘nepnieuws’ en ‘onbevestigd’.
Lifetime en het effect van de power law
Uit het onderzoek bleek dat berichten met bevestigd nepnieuws langer in WhatsAppgroepen rond bleven gaan. Berichten die bevestigde onwaarheden bevatten hadden een lifetime van tien dagen terwijl andere berichten een kortere lifetime hadden. Wel merken ze op dat dit geld voor tekstberichten, voor afbeeldingen bleek uit een eerder onderzoek met dezelfde database het omgekeerde te gelden.
Ook op WhatsApp bleek dat misinformatie sneller gedeelt werd dan andere informatie. Bovendien is hier de power law weer in terug te zien. 60% van de berichten die ‘onbevestigd’ waren gedeelt door slechts 7 personen. Het is aannemelijk dat deze personen de beste positie in het netwerk hadden om meer informatie te delen. Voor misinformatie werd 60% van de berichten gedeelt door slechts 2 personen. Voor misinformatie lijkt het effect van de power law dus meer aanwezig. Hier heeft een nog kleinere groep de meeste invloed op de misinformatie die verspreid wordt.
Uit deze onderzoeken komt naar voren dat misinformatie zich niet anders gedraagt qua deel-gedrag dan andere informatie in OSN’s. Wel wordt misinformatie langer gedeelt zodra er meer interesse in is, terwijl dit voor wetenschapsnieuws en andere informatie niet geldt. Verder wordt misinformatie meer gedeelt onder groepen met dezelfde interesses dan wetenschapsnieuws. Tot slot geldt de power law sterker voor misinformatie dan voor andere informatie.
Echter lag de focus bij beide deze onderzoeken op misinformatie m.b.t. de politiek en ideologie. De corona-crises brengt wellicht een ander soort nepnieuws met zich mee.
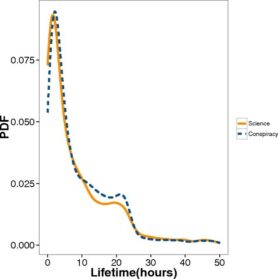
Figuur 2: lifetime van nieuwberichten en conspiracy berichten op facebook
Bron: https://www.pnas.org/content/pnas/113/3/554/F1.large.jpg
{kind=link}
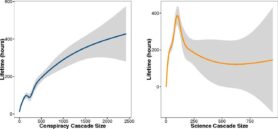
Figuur 3: de lifetime van conspiracy- (links) en wetenschapsnieuwsberichten (rechts) uitgezet tegenover hun cascade size.
Bron: https://www.pnas.org/content/113/3/554
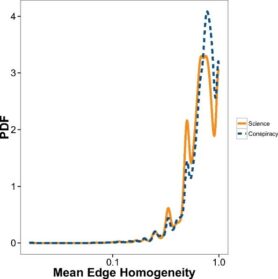
Figuur 4: homegeniteit en cascade size
Bron: https://www.pnas.org/content/pnas/113/3/554/F4.large.jpg
{kind=link}
9 Medische misinformatie
Een onderzoek van (Waszak, Kasprzycka-Waszak, & Kubanek, 2018) over medische nepnieuws tussen meerdere OSN’s laat dit zien. Dit onderzoek werd in het Pools uitgevoerd. De onderzoekers gingen op zoek naar de meest gedeelde weblinks op sociale media die zich relateerde aan de meest voorkomende doodsoorzaken[11]. Ze hebben vervolgens al deze weblinks gecontroleerd op waarheid. Ze categoriseerde de weblinks volgens; nepnieuws waaronder: ‘gefabriceerd nieuws’, ‘gemanipuleerd nieuws’, ‘adverterend nieuws’; en ook in ‘irrelevant nieuws’ en ‘voldoenend nieuws’.
Hieruit kwam dat wel 40% van de gedeelde weblinks tot nepnieuws behoorde. Bovendien kon meer dan 20% van de gevaarlijke weblinks getraceerd worden tot slechts één bron. Ook als het gaat om medische misinformatie lijkt er dus sprake van een sterke effect van de power law.
Niet alle aandoeningen lijken echter op het coronavirus. Het meest vergelijkbare is HIV, ook een virus. Van de top 10 gedeelde links over AIDS en HIV bleken 7 van de 10 nepnieuws. Mocht er een een vaccin komen voor het coronavirus dan kan daar ook nepnieuws van verwacht worden; 9 van de 10 meest gedeelde weblinks over vaccinaties bleek nepnieuws te zijn. Ter vergelijking, van kanker was dit 5/10, tumoren 2/10, diabetes 3/10 en hoge bloeddruk 7/10.
10 Conclusie
Samenvattend, misinformatie rondom het coronavirus is niet een opzichzelfstaand fenomeen. Rondom voorgaande epidemieën ging er ook misinformatie rond en dat heeft ernstige gevolgen gehad. Ook rond COVID-19 heeft misinformatie al zeker een slachtoffer teweeg gebracht. Om meer ernstige gevolgen van nepnieuws te voorkomen is het belangrijk dat correcte informatie mensen bereikt voordat misinformatie dat doet.
Misinformatie verspreidt zich sneller dan correcte informatie, blijft langer gedeelt worden en heeft minder interesse nodig dan correcte informatie. In echokamers, groepen gebruikers met dezelfde interesses, zijn deze effecten versterkt. In deze subnetwerken is er minder controle van feiten doordat de gebruikers in deze groepen hun wereldbeeld alsmaar bevestigd zien worden. (confirmation bias) Ook als het gaat over medische nepnieuws zijn in deze groepen slechts een klein aantal gebruikers de bron van het grootste deel van de misinformatie. Daarnaast kunnen berichten die veel gedeelt worden op den duur veranderen.
11 Discussie
Hoewel er door de komst van sociale media iedereen nu een redacteur is geworden van zijn eigen dagblad, blijft het risico op nepnieuws door een kleine groep groot. Ditmaal niet van een hoofdredacteur die aan de top staat en kiest welk beeld hij wilt schetsen, maar door de power law die stelt dat sommige mensen in een sociaal netwerk nou eenmaal meer invloed hebben dan andere. In zo een situatie moeten we meer doen dan alleen hopen dat de mensen in die posities zich verantwoordelijk gedragen.
Ook in Nederland, Europa en de wereld is er een risico op een tweede golf corona-patiënten indien we ons teveel laten beïnvloeden door nepnieuws. Bij de Ebola-uitbraak zorgde dit voor een vertienvoudiging van het aantal patiënten in Guinee. Hoewel ik niet verwacht dat de situatie dit keer zover uit de hand zal lopen[12], moeten we wel waakzaam zijn. Naast de verhalen over wondermiddelen tegen corona, die schadelijk kunnen zijn, schat ik in dat er ook over een toekomstig preventiemiddel in de vorm van een vaccinatie nepnieuws zal zijn.
Nepnieuws en misinformatie verspreiden zich voornamelijk binnen echokamers, maar binnen deze subnetwerken zijn er slechts een klein aantal gebruikers die het grootste deel van de gedeelde misinformatie verspreiden. Het is de vraag of het mogelijk is om dit te stoppen. Naast dat het lastig kan zijn om zo een gebruiker ervan te overtuigen dat wat er gedeeld wordt incorrect en schadelijk is, is er ook een kans dat er gewoonweg andere gebruikers komen die dezelfde rol overnemen.
Een goede manier om de schade van misinformatie te beperken lijkt mij door gebruikers correcte informatie te geven voordat ze de misinformatie tegenkomen. Ik geloof dat wij als studenten met toegang tot een boel wetenschappelijke informatie hier een grote rol in kunnen spelen. Hoewel het een grote en enge verantwoordelijkheid is.
Enkele grote OSN-platformen waarop misinformatie verspreid wordt hebben al maatregelen genomen. Google en dochterbedrijf YouTube tonen bij alles waarbij ze vermoeden dat het corona gerelateerd is al informatie van gezondheidsinstanties en betrouwbare nieuwsbronnen over het virus. Twitter, Facebook en Amazon geven advertentieruimte weg aan organisaties. (Waddel, 2020) Daarnaast nemen ze nog meer maatregelen.
Ik vermoed dat dit soort maatregelen voor de messenger-OSN’s lastiger zal zijn. Die kenmerken zich door hun privé gesprekken en hun gebruikers zouden waarschijnlijk raar opkijken als het bedrijf direct communiceert met zijn gebruikers via de apps. Ze zijn immers al huiverig over advertenties in hun apps. Berichten controleren gaat ook niet, juist omdat de correspondenties privé zijn. Op dit gebied moeten we elkaar dus scherp houden.
12 Eindconclusie
Voor ons onderzoek gedurende blok 4 is het handig om rekening te houden met de volgende dingen. In elk (sub)netwerk zijn er slechts een aantal gebruikers die het grootste deel van de nepnieuws verspreiden. Een goed beeld van hun berichten geeft dus een aardige beeld van hun subnetwerk. Andersom zal een subnetwerk waarschijnlijk gedomineerd worden door berichten die zijn te herleiden tot een aantal gebruikers. Als het gaat om misinformatie lijkt dit effect versterkt. Verder volgen beide misinformatie en correcte informatie hetzelfde patroon qua deel gedrag. Voor beide geldt dat een groot deel van de berichten niet langer dan 2 uur worden gedeelt en de meeste niet langer dan een dag. Berichten met misinformatie waar veel interesse voor is (je zou kunnen zeggen hype) worden langer gedeelt, terwijl berichten met correcte informatie waar veel interesse voor is niet per se langer worden gedeelt.
Hierom stel ik voor om bij het close-reading deel van het onderzoek te kijken naar de berichten waar veel interesse in is. Het liefst ook een bericht die komt van een bron in het netwerk met veel invloed, deze zou geïdentificeerd kunnen worden a.d.h.v. een frequentie analyze op een groot deel van de berichten in een subnetwerk. Mocht dit niet lukken kunnen we er rekening mee houden dat berichten met weinig participatie waarschijnlijk niet representatief zijn voor het hele subnetwerk.
13 Verwijzingen
Allport, G., & Postman, L. (1947). The psychology of rumor. In H. Holt, The psychology of rumor (p. 247). Oxford: Heny Holt and Company.
Andrews, E. (2019, oktober 9). How fake news spreads like a real virus. Opgehaald van Stanford Engineering: https://engineering.stanford.edu/magazine/article/how-fake-news-spreads-real-virus
Castillo, C., Mendoza, M., & Poblete, B. (2011). Information Credibility on Twitter. Proceedings of the 20th international conference on World wide web (pp. 675-684). New York: Association for Computing Machinery.
Del Vicario, M., Bessi, A., Zollo, F., Petroni, F., Scala, A., Caldarelli, G., . . . Quattrociocchi, W. (2016). The Spreading of misinformation online. National Academy of Sciences, 554-559.
Faloutsos, M., Faloutos, P., & Faloutsos, C. (1999). On Power-Law Relationships of the Internet Topology. Computer Communication Review, 251-262.
Gans, H. (1979). Deciding What’s News. New York: Pantheon Books.
Gans, H. (1979). The messages behind the news. Columbia Journalism Review, 17(5), 40.
Mian, A., & Khan, S. (2020). Coronavirus: the spread of misinformation. BMC Medicine, 1-2.
Mossa, S., Barthélémy, M., Stanley, E., & Nunes Amaral, L. (2002). Truncation of Power Law Behavior in “Scale-Free” Network Models due to Information Filtering. Physical Review Letters, 138701/1-138701/4.
Nguyen, N., Yan, G., Thai, M., & Eidenbenz, S. (2012). Containment of Misinformation Spread in Online Social Networks. Proceedings of the 4th Annual ACM Web Science Conference (p. 213). New York: Association for Computing Machinery.
Resende, G., Melo, P., Reis, J., Vasconcelos, M., Almeida, J., & Benevenuto, F. (2019). Analyzing Textual (Mis)Information Shared in WhatsApp Groups. Proceedings of the 10th ACM Conference on Web Science (pp. 225-234). New York: Association for Computing Machinery.
Silverstein, B. (1987). Toward a Science of Propaganda. Political Psychology, 49-59.
Sosnovsky, S. (2020, februari 5). Brief History of the Web. Utrecht, Utrecht, Nederland.
Stern, J. E. (2014, september 2). Hell in the Hot Zone. Opgehaald van Vanityfair: https://www.vanityfair.com/news/2014/10/ebola-virus-epidemic-containment
The Guardian. (2020, maart 24). Arizona man dies after attempting to take Trump coronavirus ‘cure’. Opgehaald van The Guardian: https://www.theguardian.com/world/2020/mar/24/coronavirus-cure-kills-man-after-trump-touts-chloroquine-phosphate
US Centers for Disease Control and Prevention. (2019, april 3). Ebola (Ebola Virus Disease) 2014 Ebola Outbreak in West Africa Epidemic Cruves. Opgehaald van Centers for Disease Control and Prevention: https://www.cdc.gov/vhf/ebola/history/2014-2016-outbreak/cumulative-cases-graphs.html
US Centers for Disease Control and Prevention. (2019, November 5). Ebola (Ebola Virus Disease) symptoms. Opgehaald van Centers for Disease Control and Prevention: https://www.cdc.gov/vhf/ebola/symptoms/index.html
Waddel, K. (2020, maart 11). Fight Against Coronavirus Misinformation Shows What Big Tech Can Do. Opgehaald van bridgeportedu: https://www.bridgeportedu.net/cms/lib/CT02210097/Centricity/Domain/3754/Costello_Journalism_11_3_23.3_31.pdf
Waszak, P., Kasprzycka-Waszak, W., & Kubanek, A. (2018). The spread of medical fake news in social media – The pilot quantitative study. Health Policy and Technology, 115-118.
[1] Benaming voor Spanje onder Franco
[2] Vrije vertaling vanuit het Engels: “The media could have called the young men who refused to serve in the Vietnam War draft evaders, dodgers or risters,” (Gans H. , 1979)
[3] “We want to to make sure that most of the network users are aware of the good information by the time the bad one reaches them.” (Nguyen, Yan, Thai, & Eidenbenz, 2012)
[4] ‘ “rebels dressed in yellow who attacked Guinea and then disappeared”—the interpretation of a local journalist trying to make sense of all the people in big yellow protective suits who had suddenly descended on the country. ’ (Stern, 2014)
[5] De incubatietijd, de lengte van de periode tussen het oplopen van het virus en het tonen van de eerste symptomen bij een patiënt, bedragen bij ebola hoogstens 21 dagen na contact met het virus. (US Centers for Disease Control and Prevention, 2019)
[6] Web 1.0 (1989-2003) was voornamelijk voor mensen met maar relatief klein aantal auteurs. Web 2.0 (2004-2011) bracht daar verandering in. Mede door de opkomst van OSN’s kreeg het WWW plots veel meer auteurs. Inmiddels zitten we in Modern Web (2011- … waarbij zelfs algoritmes content consumeren en produceren voor het web. (Sosnovsky, 2020)
[7] “The so-called “power law’” of social media, a well-documented pattern in social networks, holds that messages replicate most rapidly if they are targeted at relatively small numbers of influential people with large followings.”
[8] Waarbij een verhaal of een zin wordt doorgefluisterd van persoon A naar persoon B en persoon van persoon B naar persoon C tot de laatste persoon in de ketting die het verhaal probeert te herhalen.
[9] Hiervoor gebruikte Resende et al de Jaccards gelijkheidscoëfficiënt en beschouwde ze berichten met een geleikheidsscore vanaf 0,7 als het zelfde bericht.
[10] Aangegeven bij cascade size.
[11] Ze gerbuikten als zoektermen: cancer, neoplasm, heart attack, stroke, hypertension, diabetes, vaccinations, HIV, and AIDS.
[12] COVID-19 heeft immers een kortere incubatietijd dan het Ebolavirus.
Combineren van kwalitatieve en kwantitatieve methoden om nepnieuws te detecteren
1 Inleiding
Steeds meer mensen volgen het nieuws online. Tegenwoordig heeft bijna elke volwassene een smartphone of laptop waarmee het nieuws makkelijk en gratis gevolgd kan worden. Hierdoor neemt het aantal gebruikers dat nieuws ontvangt via de traditionele offlinemethoden, zoals kranten en weekbladen, sterk af.
Uit onderzoek blijkt dat steeds meer mensen nieuws verkrijgen via gerenommeerde nieuwssites zoals nos.nl en nu.nl (Wennekers, de Haan 2017). Bovendien worden sociale media platforms als Facebook en Twitter ook steeds populairder als informatiebronnen.
Er is alleen één probleem met het online verkrijgen van nieuws; iedereen kan (foutieve) informatie over het internet verspreiden. Waar Facebook haar gebruikers meestal met een link naar het originele nieuwsbericht stuurt, wordt het nieuws op Twitter vooral door de gebruiker zelf de wereld in gebracht (PEW Research Center 2012). Door deze user generated content ontstaat nepnieuws, waardoor lezers op het verkeerde been kunnen worden gezet.
In dit paper wordt een plan besproken waarmee nepnieuws onderscheiden zou kunnen worden van feitelijk nieuws. Ten eerste zal kort worden toegelicht wat nepnieuws precies is en waarom het juist nu zo’n groot probleem is. Ten tweede zal er worden gekeken naar het gebruik van kwalitatief onderzoek. Dit zal verschillende teksten op basis van lexicon, syntax en woordkeuze analyseren. Ten derde zal er een kwantitatieve methode aan bod komen. Hiervoor zal een fact-checking programma gebruikt worden dat nep nieuws kan opsporen. Tenslotte zullen deze twee methodes gecombineerd worden, waardoor het algoritme, met de informatie verkregen uit het kwalitatieve onderzoek, een goede schatting zou moeten kunnen maken over welk nieuws echt en welk nieuws nep is.
2 Wat is nepnieuws?
Er is geen duidelijke definitie voor de term nepnieuws. In dit paper zal de definitie worden gebruikt zoals deze door A. Gelfert, onderzoeker aan de Technische Universiteit van Berlijn, beschreven is: nepnieuws is het opzettelijk presenteren van foutieve of misleidende claims als nieuws (A. Gelfert, 2018).
Vanaf de Amerikaanse presidentsverkiezingen in 2016 werd nepnieuws pas echt als een probleem gezien. Er werd toen een onderzoek gedaan naar het bereik van nepnieuws en de resultaten waren erg indrukwekkend. Het bleek dat de twintig meest besproken nepnieuws artikelen 8.711.000 aandelen, reacties en commentaren op Facebook genereerden, tegenover een kleiner totaal van 7.367.000 voor de twintig meest besproken verkiezingsartikelen, geplaatst door gerenommeerde nieuwswebsites (Silverman 2016).
Onderzoek naar nepnieuws kan gedaan worden vanuit vier perspectieven: (1) knowledge-based, dat gefocust is op de foutieve informatie in nepnieuws, (2) style-based, dat zich bezighoudt met de manier waarop nepnieuws geschreven is, (3) propagation-based, gefocust op hoe nepnieuws zich verspreid en (4) credibility-based, dat betrokken is bij de betrouwbaarheid van de auteur en de verspreiders van het nieuws (Zhou en Zafarani, 2018).
Dit stuk zal gefocust zijn op de eerste twee perspectieven. Voor de kwalitatieve methode zal style-based onderzoek worden gedaan en voor de kwantitatieve methode is knowledge-based onderzoek nodig. In het volgende deel zal de style-based methode verder toegelicht worden, waarna ook de knowledge-based methode verder zal worden uitgewerkt.
3 Style-based onderzoek naar nepnieuws
Bij de style-based methode wordt er vooral onderzocht wat de intentie is van bepaald nieuws. Deze informatie kan gebruikt worden bij het achterhalen of bepaald nieuws nep is of niet. De analyse en detectie van misleidingen maakt gebruikt van de style-based methode. Deze studies zijn voornamelijk bezig met (1) deception style theories, waarom de stijl van de inhoud van een tekst kan helpen bij het opsporen van nepnieuws, (2) style-based features and patterns, die nepnieuws kunnen representeren en vastleggen en (3) deception detection strategies die onderzoeken hoe stijl gebruikt kan worden in het detecteren van nepnieuws.
Alle drie zullen nu verder toegelicht worden.
3.1 Deception style theories
Intuïtief zou het logisch zijn als misleidend nieuws qua inhoudsstijl zou verschillen van de waarheid. Dit komt omdat de schrijvers van foutieve informatie vaak mensen willen misleiden met overdreven uitdrukkingen en sterke emoties. Ook forensisch-psychologische onderzoeken hebben aangetoond dat teksten die zijn afgeleid van feiten, verschillen van teksten die gebaseerd zijn op verzonnen verhalen (Siering et al. 2016). Verschillende latere onderzoeken hebben bevestigd dat onderzoeken die inhoudsstijl gebruiken om misleiding op te sporen, goed werken. Het detectie-niveau van deze onderzoeken varieerde tussen de 60% en de 90% (Zhou en Zafarini, 2018).
3.2 Style-based features and patterns
Inhoudsstijl wordt gewoonlijk gerepresenteerd door kwantificeerbare karakteristieken. Deze karakteristieken kunnen worden verdeeld in twee sub-categorieën; attribute-based language features en structure-based language features. Om te begrijpen wat de verschillen zijn worden beide groepen hieronder toegelicht.
Attribute-based language features zijn meestal gebaseerd op de eerdergenoemde deception style theories. De kenmerken van nieuwsberichten kunnen worden gegroepeerd in tien categorieën; kwantiteit, complexiteit, onzekerheid, subjectiviteit, niet-directheid, sentiment, diversiteit, informaliteit, specificiteit en leesbaarheid. Deze attribute-based language features zeggen veel over de waarheid van een tekst en zijn erg verklaarbaar. Er zitten echter ook nadelen aan deze aanpak. De kenmerken zijn namelijk vaak moeilijk te kwantificeren. Specifieke kenmerken hebben vaak een extra herhaling van detectie nodig en dat kost veel tijd.
Om te bepalen welke categorieën van kenmerken het meest relevant zijn voor de detectie van nepnieuws, hebben X. Zhou en R. Zafarani verschillende onderzoeken naast elkaar uit gezet (Tabel 1) (Zhou en Zafarini, 2018). In deze tabel is te zien dat misleidende berichten hogere niveaus van kwantiteit, niet-directheid en informaliteit tonen, terwijl diversiteit en specificiteit juist lager scoren bij foutieve informatie. Toekomstige onderzoeken kunnen met behulp van deze informatie preciezere style-based detectie programma’s schrijven.
Tabel 1: Patronen van misleidende attribute-based language features

Structure-based language features beschrijven de inhoudsstijl van informatie op vier taalniveaus; (1) lexicon, (2) syntax, (3) semantiek en (4) dialoog. Het kwantificeren van structure-based language features berust vooral op Natural Language Processing (NLP). NLP is een sub gebied van taalkunde, informatica en kunstmatige intelligentie, dat zich bezighoudt met de manier waarop computers grote hoeveelheden natuurlijke taalgegevens verwerken en analyseren (Liddy, 2001). Op lexicon-niveau is de belangrijkste taak van NLP om de frequentie van letters, woorden enz. te beoordelen. Op syntax-niveau houdt het zich bezig met de grammatica van zinnen. Op semantisch niveau gaat het om de betekenis van verschillende woorden en zinnen. En tenslotte traceert NLP op dialoog-niveau de verschillende retorische relaties tussen woordgroepen en zinsdelen. In nepnieuws detectie studies zeggen structure-based language features minder over de waarheid van een tekst, maar het berekenen van de kenmerken is relatief eenvoudig ten opzichte van attribute-based language features.
3.3 Deception detection strategies
Er is nog weinig onderzoek beschikbaar over deception detection strategies, maar het is een erg opkomende aanpak in het opsporen van nepnieuws.
De meeste onderzoeken gebruiken supervised-learning technieken, waarbij een programma een database bezit met gelabelde training data. Aan de hand van de voorbeelden in deze database, zou het programma nieuwe input-data moeten kunnen labelen als ‘nep’ of ‘normaal’.
Er zijn echter twee problemen met deze manier van onderzoeken. Ten eerste is het aantal gelabelde voorbeelden in de database relatief klein. Dit komt doordat het handmatig labelen van voorbeelden lang niet zo snel gaat als de snelheid waarin nieuwe informatie wordt gecreëerd op sociale media. Ten tweede is het moeilijk om een perfecte database te maken, aangezien mensen slecht zijn in het identificeren van nepnieuws. Sociale psychologie- en communicatiestudies tonen aan dat het menselijk vermogen om nepnieuws te detecteren slechts een paar procent beter is dan toeval. De gemiddelde nauwkeurigheid van 1000 deelnemers aan meer dan 100 experimenten is 54% (Rubin, 2010). In volgende onderzoeken zou semi-supervised learning dan ook een grote rol kunnen spelen bij het verbeteren van nepnieuws detectie programma’s. Hierbij is niet alle data gelabeld, maar is er ook nog een groot deel ongelabelde data. Op deze manier kan een programma zichzelf meer aanleren, dan alles van een ‘supervisor’ na te bootsen.
Aan de hand van style-based onderzoek kunnen teksten dus kwalitatief geanalyseerd worden. Bij deze strategie bestuderen onderzoekers bepaalde kenmerken in de inhoudsstijl. Hierbij kan gekozen worden voor het analyseren van attribute-based language features of structure-based language features. Later zal duidelijk worden op welke manier deze gegevens kunnen helpen om nepnieuws te detecteren.
4 Knowledge-based onderzoek naar nepnieuws
Net zoals bij style-based onderzoek, gaat het bij knowledge-based onderzoek over het bestuderen van de inhoud van een tekst. Bij de knowledge-based methode gaat het echter over de waarheid van een tekst, waar het bij style-based studies gaat over de intentie van de schrijver van een tekst.
Om de waarheid van een tekst te achterhalen, gebruikt de knowledge-based methode de fact-checking strategie. Het doel van deze strategie is, zoals de naam al zegt, het checken van feiten in een tekst. Er zullen twee verschillende methoden worden besproken voor fact-checking. Ten eerste zal kort de traditionele vorm aan bod komen, waarna de automatische vorm toegelicht zal worden.
4.1 Handmatige fact-checking
Bij deze vorm van fact-checking worden teksten gecontroleerd door mensen. Dit kan zowel door experts gedaan worden (expert-based) als door groepen mensen (crowd-sourced). Ook deze twee verschillende benaderingen zullen kort toegelicht worden.
Expert-based fact-checking is afhankelijk van experts per domein. Deze manier van fact-checking wordt vaak uitgevoerd door een kleine groep van erg betrouwbare experts. Hierdoor zijn de resultaten erg nauwkeurig, maar kost de methode ook een hoop geld. Bovendien stijgt het aantal beoordeelde gegevens een stuk langzamer dan het aantal te controleren nieuws.
Crowd-sourced fact-checking is afhankelijk van een groot aantal individuen die zullen optreden als fact-checkers. In vergelijking met expert-based fact-checking is deze methode erg moeilijk te controleren. Daarnaast zijn de resultaten minder geloofwaardig en precies, doordat mensen beoordelen vanuit hun eigen perspectief. Daarentegen staat wel dat deze methode heel wat sneller gaat doordat het aantal fact-checkers een stuk groter is. Deze vorm van controleren is echter nog steeds niet snel genoeg om de grote hoeveelheid aan nieuwe gegevens bij te houden.
4.2 Automatische fact-checking
Om de snelheid van opkomend te controleren nieuws bij te kunnen blijven, zijn er automatische technieken ontwikkeld. Deze maken gebruik van Information Retrieval (IR) en Natural Language Processing (NLP). In afbeelding 1 is globaal te zien hoe een automatisch fact-checking proces in zijn werk gaat (Zhou en Zafarani, 2018). Zoals je ziet is de procedure verdeeld in twee stadia; (1) fact-extraction en (2) fact-checking. Bij fact-extraction wordt er een knowledge-base gemaakt. Deze is opgebouwd uit gegevens van het internet, die na een data-opruiming, alleen nog maar uit feiten bestaan (Pawar et al. 2017). Bij fact-checking wordt vervolgens de te controleren input vergeleken met de knowledge-base om te bepalen of het nepnieuws is of niet. Beide fases zullen nader worden toegelicht.
Afbeelding 1: Proces automatische fact-checking
Zhou en Zafarini, 2018
Fact-extraction verloopt op zijn beurt weer in verschillende stappen. Eerst wordt er grove informatie van het internet gehaald. Deze gegevens zijn vaak verouderd, onbetrouwbaar of onvolledig. Om tot een bruikbare knowledge-base te komen, moet deze informatie grondig opgeruimd worden. De procedure zal duidelijk uiteengezet worden.
Het verkrijgen van informatie over internet wordt ook wel knowledge extraction genoemd. Onderzoekers kunnen op twee manieren gegevens verzamelen van het internet; ze kunnen één bron gebruiken (single-source), of meerdere bronnen (open-source). Single-source knowledge extraction haalt zijn informatie van één betrouwbare bron (zoals nos.nl). Deze methode is erg efficiënt, maar resulteert vaak in incomplete kennis (Auer et al. 2007). Open-source knowledge extraction daarentegen, gebruikt gegevens van meerdere bronnen. Dit leidt tot minder efficiënte informatie, maar de uiteindelijke gegevens zijn completer (Dong et al. 2014).
De data die op dit punt is verzameld, is nog verre van af. Zo kan de informatie overbodig, ongeldig, tegenstrijdig, onbetrouwbaar en incompleet zijn. Om deze gebreken te verhelpen moeten de volgende taken uitgevoerd worden (de precieze technieken worden niet toegelicht in dit paper):
Ten eerste wordt het oplossen van entiteiten (Steorts et al. 2016) gebruikt om overbodige informatie te verwijderen. Deze methode probeert in de knowledge-base woordgroepen te zoeken die naar dezelfde entiteit verwijzen (Culotta en McCallum, 2005). Zo verwijzen ‘Barack Obama’ en ‘Barack Hussein Obama’ naar dezelfde persoon, terwijl het verschillende woordgroepen zijn.
Ten tweede wordt tijdregistratie gebruikt om verouderde data bij te werken. Soms worden gegevens na een bepaalde tijd ongeldig. Zo is ‘Barack Obama wordt president van de Verenigde Staten’ tegenwoordig niet meer geldig. Deze informatie moet dan verwijderd of bijgewerkt worden (Bollacker et al. 2008).
Ten derde wordt kennisfusie toegepast om tegenstrijdige informatie aan te pakken. Het probleem van tegenstrijdige informatie komt vooral voor wanneer er open-source knowledge extraction wordt toegepast. In dit geval wordt er gekeken naar de betrouwbaarheid van de websites waar de gegevens vandaan zijn gehaald. Hiermee kan uiteindelijk bepaald worden welke data verwijderd moet worden en welke niet (Esteves et al. 2018).
Ten vierde is er de evaluatie van waarheid, die wordt gebruikt om de geloofwaardigheid van gegevens te verbeteren. Ook bij deze methode worden de bronnen waarvan data is verzameld onderzocht op betrouwbaarheid. Hierbij wordt niet alleen de inhoud van de bronnen beoordeeld, maar ook de links naar andere websites die door de bronnen worden gegeven worden goed onderzocht (Dong et al. 2015).
Tenslotte wordt voorspelling van relaties toegepast om nieuwe feiten af te leiden. Wanneer data van één enkele bron wordt gebruikt, is de informatie vaak verre van compleet. Het is dus noodzakelijk om nieuwe informatie af te kunnen leiden van al bekende informatie om tot een complete knowledge-base te komen (Nickel et al. 2016).
Door het volgen van deze vijf stappen kan een goede knowledge-base gecreëerd worden die we kunnen gebruiken in de volgende fase.
Fact-checking gaat na het maken van de knowledge-base de te controleren gegevens beoordelen. Hiervoor zal de input vergeleken moeten worden met de feiten uit de knowlegde-base. Dit wordt onderzocht door middel van SPO-triples. Dit is een set van (Subject, Predicate, Object) trio’s, die uit de knowledge-base worden gehaald. Wanneer er een trio gevonden wordt in de te onderzoeken gegevens, wordt er gekeken of er in de knowledge-base eenzelfde trio bestaat. Dit gebeurt in drie stappen:
Ten eerste moet de entiteit worden gelokaliseerd. In deze stap wordt het subject van trio gelinkt aan een entiteit. Hierin is het weer belangrijk dat twee verschillende woordgroepen naar dezelfde entiteit kunnen wijzen. Entity resolution technieken kunnen gebruikt worden voor het matchen van subjects aan entiteiten (Getoor en Machanavajjhala, 2012).
Ten tweede moet de relatie tussen subject en object geverifieerd worden. Het trio (Obama, beroep, president) is bijvoorbeeld alleen waar als dit trio ook bestaat in de knowledge-base. Als dit niet het geval is, dan worden de gegevens (1) beschouwd als onwaar (close world assumption) of (2) verder gecontroleerd in de laatste stap (Reiter, 1981).
In de laatste stap worden de gegevens die nog niet als waar of onwaar zijn bestempeld nog verder beoordeeld. Hiervoor wordt de voorspelling van links gebruikt, waarmee nieuwe informatie kan worden afgeleid van al bekende gegevens. De resultaten die hieruit komen worden weer vergeleken met de feiten uit de knowledge-base. Op deze manier kan uiteindelijk besloten worden of de informatie waar of onwaar is.
Door middel van knowledge-based onderzoek kunnen gegevens handmatig en automatisch gecontroleerd worden op waarheid. Bij de automatische methode voor fact-checking wordt op een kwantitatieve manier gecheckt of input nepnieuws is of niet. In het volgende gedeelte zal toegelicht worden hoe we deze kwantitatieve methode nog meer kunnen gebruiken.
5 Combineren van kwalitatief en kwantitatief onderzoek
De aanleiding voor het combineren van kwalitatief en kwantitatief onderzoek is dat de verschillende methoden verschillende krachten hebben. De kwalitatieve methode doet onderzoek naar variatie van data op een kleinere schaal en de kwantitatieve methode doet onderzoek naar hoeveelheden van bepaalde kenmerken op een grotere schaal. Door ze samen te voegen, breng je het vermogen van beide methoden samen in één onderzoek. Om kwalitatief en kwantitatief onderzoek te combineren moet een onderzoeker zichzelf twee vragen stellen (Morgan, 1998):
5.1 Welke methode wordt de belangrijkste methode in het onderzoek en welke zal aanvullend zijn?
De onderzoeker zal eerst moeten bepalen of de kwalitatieve of de kwantitatieve methode als hoofdmethode zal dienen. Er bestaat natuurlijk de kans dat beide methoden even belangrijk worden beschouwd, wat leidt tot problemen (Morse, 1991). De twee onderzoeken zouden in dat geval in een samenhangend verband moeten verlopen, waarna er een derde stap nodig is om de twee te verbinden. Bovendien kan de informatie, gevonden in de verschillende onderzoeken, tegenstrijdig zijn.
Een praktischere methode is om een enkele strategie te kiezen als hoofdmethode en de ander te gebruiken als complementaire strategie. Om deze beslissing te maken, moet de onderzoeker nagaan welke methode de resultaten zal verkrijgen die het belangrijkst zijn om de onderzoeksvraag te beantwoorden. Als de hoofdmethode is gekozen, zal de onderzoeker moeten bepalen op welke manier de andere methode kan helpen bij het vergrijgen van de beste resultaten.
5.2 Zal de aanvullende methode voorafgaan aan de hoofdmethode, of zal de aanvullende methode volgen op de hoofdmethode?
Wanneer de hoofdmethode en de aanvullende methode zijn gekozen, moet de volgorde van de twee worden bepaald. Ook hier is weer de belangrijkste vraag: hoe kunnen de twee verschillende methoden het best verbonden worden om optimale resultaten te verkrijgen? Bij het beantwoorden van deze vraag is het belangrijk om na te denken over de hoofdmethode.
In het begin van een onderzoek is het belangrijkste doel om de effectiviteit van de hoofdmethode te optimaliseren. Dit kan door een inleidende methode te gebruiken, die de data voor de hoofdmethode kan perfectioneren. Tegen het eind van een project is het doel om de resultaten die verkregen zijn te maximaliseren. In dit geval kan een onderzoek beëindigd worden door het gebruiken van een tweede methode, die de bestaande resultaten kan optimaliseren.
De volgorde van de twee methodes hangt dus niet zoveel af van of ze kwalitatief of kwantitatief zijn. Het gaat er vooral om of de aanvullende methode een grotere bijdrage kan leveren voorafgaand aan de hoofdmethode, of volgend op de hoofdmethode.
Nu er een duidelijker beeld geschetst is over hoe kwalitatief en kwantitatief onderzoek het best gecombineerd kunnen worden, zullen beide vragen beantwoord worden aan de hand van het kwalitatieve en kwantitatieve onderzoek dat eerder besproken is.
Eerst zal er bepaald moeten worden welke methode de belangrijkste methode wordt. Het doel van het onderzoek is om nepnieuws te kunnen detecteren. Hiervoor kunnen we als hoofdmethode het best de kwantitatieve strategie nemen, aangezien deze grote hoeveelheden data snel kan analyseren. De kwalitatieve methode kan gebruikt worden als aanvullende methode.
Hierna zal de onderzoeker moeten bepalen of de kwalitatieve methode voorafgaand of na de kwantitatieve methode zal gebeuren. In het onderzoek naar nepnieuws zal de kwalitatieve methode erg handig van pas komen om de knowledge-base voor het kwantitatieve onderzoek te creëren. Dit betekent dat het kwalitatieve onderzoek voorafgaand aan de hoofdmethode zal plaatsvinden.
Op deze manier kan de kwalitatieve methode door middel van style-based onderzoek verschillende teksten analyseren op kenmerken in de inhoudsstijl. De resultaten van dit onderzoek kunnen daarna in de knowledge-base van de kwantitatieve methode gebruikt worden, waarna deze de data uit zijn knowledge-base zal vergelijken met de te controleren data. De resultaten uit dit laatste onderzoek zullen aantonen welke gegevens nepnieuws zijn en welke niet.
6 Conclusie
Nepnieuws is tegenwoordig een erg groot probleem. Iedereen kan foutieve informatie verspreiden over sociale media en het menselijke vermogen om nepnieuws te detecteren is erg klein. In dit paper is een methode besproken om nepnieuws te kunnen detecteren aan de hand van kwalitatief en kwantitatief onderzoek. Kwalitatief onderzoek analyseert teksten door te kijken naar kenmerken in inhoudsstijl. Het kwantitatieve onderzoek gebruikt deze resultaten om zijn knowledge-base op te bouwen. Hierna kan de input data vergeleken worden met de feiten uit de knowledge-base, waardoor gecontroleerd zal worden welke input nepnieuws is en welke niet.
7 Geraadpleegde bronnen
Ali, M. & Levine, T. (2008). The language of truthful and deceptive denials and confessions
Anderson, E. T. & Simester, D. I. (2014). Reviews without a purchase: Low ratings, loyal customers, and deception
Auer S., Bizer, C., Kobilarov, G., Lehmann, J., Cyganiak, R. & Ives, Z. (2007). Dbpedia: A nucleus for a web of open data
Bollacker, K., Evans, C., Paritosh, P., Sturge, T. & Taylor, J. (2008). Freebase: a collaboratively created graph database for structuring human knowledge
Bond, G. D. & Lee, A. Y. (2005). Language of lies in prison: Linguistic classification of prisoners’ truthful and deceptive natural language
Braun, M. T. & Van Swol, L. M. (2016). Justifications offered, questions asked, and linguistic patterns in deceptive and truthful monetary interactions
Culotta, A. & McCallum, A. (2005). Joint deduplication of multiple record types in relational data
Derrick, D. C., Meservy, T. O., Jenkins J. L., Burgoon, J. K. & Nunamaker J. F. (2013). Detecting deceptive chat-based communication using typing behavior and message cues
Dong, X. L., Gabrilovich, E., Heitz, G., Horn, W., Lao, N., Murphy, K., Strohmann, T., Sun, S. & Zhang, W. (2014). Knowledge vault: A web-scale approach to probabilistic knowledge fusion
Dong, X. L., Gabrilovich, E., Murphy, K., Dang, V., Horn, W., Lugaresi, C., Sun, S. & Zhang, W. (2015). Knowledge-based trust: Estimating the trustworthiness of web sources
Esteves, D., Reddy, A. J., Chawla, P. & Lehmann, J. (2018). Belittling the Source: Trustworthiness Indicators to Obfuscate Fake News on the Web
Fuller, C. M., Biros, D. P. & Wilson, R. L. (2009). Decision support for determining veracity via linguistic-based cues
Gelfert, A. (2018). Fake news: a definition
Getoor, L. & Machanavajjhala, A. (2012). Entity resolution: theory, practice & open challenges
Hancock, J. T., Curry L. E., Goorha, S. & Woodworth, M. (2007). On lying and being lied to: A linguistic analysis of deception in computer-mediated communication
Humpherys, S. L., Moffitt, K. C., Burns, M. B., Burgoon J. K. & Felix, W. F. (2011). Identification of fraudulent financial statements using linguistic credibility analysis
Liddy, E. D. (2001). Natural Language Processing.
Matsumoto, D. & Hwang, H. C. (2015). Differences in word usage by truth tellers and liars in written statements and an investigative interview after a mock crime
Morgan, D. L. (1998). Practical strategies for combining qualitative and quantitative methods: applications to health research
Morse, J. M. (1991). Approaches to qualitative-quantitative triangulation
Newman, M.L., Pennebaker, J. W., Berry, D. S. & Richards, J. W. (2003). Lying words: Predicting deception from linguistic styles
Nickel, M., Murphy, K., Tresp, V. & Gabrilovich, E. (2016). A review of relational machine learning for knowledge graphs
Pawar S., Palshikar, G. K. & Bhattacharyya, P. (2017). Relation Extraction: A Survey
Pew, R.C. (2012). In changing news landscape, even television is vulnerable. Trends is news consumption: 1991 – 2012
Reiter, R. (1981). On closed world data bases
Rubin V. L. (2010). On deception and deception detection: Content analysis of computer- mediated stated beliefs
Siering et al. (2016). Detecting fraudulent behavior on crowdfunding platforms: The role of linguistic and content-based cues in static and dynamic contexts
Silverman, C. (2016). This analysis shows how viral fake election news stories outperformed real news on Facebook
Steorts, R. C., Hall, R. & Fienberg, S. E. (2016). A bayesian approach to graphical record linkage and deduplication
Wennekers, A. & de Haan, J. (2017). Nederlanders en nieuws, gebruik van nieuwsmedia via oude en nieuwe kanalen
Zhou, L., Burgoon, J. K., Nunamaker, J. F. & Twitchell, D. (2004). Automating linguistics-based cues for detecting deception in text-based asynchronous computer-mediated communications
Zhou, L. & Zenebe, A. (2008). Representation and reasoning under uncertainty in deception detection: A neuro-fuzzy approach
Zhou, X. & Zafarani, R. (2018). Fake News: A Survey of Research, Detection Methods, and Opportunities
Algoritmes en een database: een advies
1 Voorwoord
In dit essay zal ik twee vragen beantwoorden met betrekking tot ons onderzoek. Om onderzoek te kunnen doen naar nepnieuws rondom het COVID-19 virus, hebben we besloten teksten te classificeren als nepnieuws of waarheid met behulp van een algoritme, wat zal worden beïnvloed door de uitkomst van een kwalitatief onderzoek naar nepnieuws. Hiervoor zijn zowel een passend algoritme als een database nodig. In dit essay zal ik over beide onderwerpen een advies geven qua aanpak en dit onderbouwen met literatuur. Om de structuur enigszins te bewaren, zal ik de vragen een voor een behandelen.
2 Welk algoritme gebruiken we?
2.1 Introductie
De keuze voor een bepaald algoritme is geen triviale. Binnen het veld dat zich bezighoudt met het computationeel verwerken van tekst (of spraak), Natural Language Processing (NLP), zijn door de jaren heen vele algoritmes ontwikkeld, waarvan sommige al meer dan 50 jaar oud zijn. Tussen al deze algoritmen bestaan subtiele verschillen die het ene algoritme net iets meer geschikt maken dan het andere. Hoe wordt dan gekozen welk algoritme het beste is?
Het antwoord op deze vraag is van meerdere factoren afhankelijk. Het is onder andere belangrijk om te weten wat het algoritme precies moet kunnen, of er meer waarde wordt gehecht aan snelheid of efficiënt omgaan met geheugen, hoe groot de database is, waar programmeurs al ervaring mee hebben, etc. Van de mogelijkheden die er zijn, ben ik er drie tegengekomen in de gelezen literatuur die goede kandidaten zijn. Voor elk algoritme zal ik kort beschrijven hoe het functioneert en de mogelijke voor- en nadelen toelichten die de keuze voor dat algoritme beïnvloeden.
2.2 Knowledge graph
De werking van een knowledge graph (kennisgraaf) wordt gedetailleerd beschreven in Zhou & Zafarani (2018) als een van de mogelijkheden om nepnieuws mee op te sporen. Wanneer een stuk tekst in een kennisgraaf wordt verwerkt, krijgt het een authenticiteitsscore. Deze geeft bijvoorbeeld weer hoeveel procent van de uitspraken in de tekst juist zijn volgens het algoritme. Een graaf is binnen de informatica een boomstructuur, met knopen en takken. In de knopen wordt ‘informatie’ opgeslagen en de takken tussen bepaalde knopen geven de relatie tussen die stukken informatie weer. Bijvoorbeeld, de knoop met het label ‘Mark Rutte’ en de knoop met het label ‘Minister-President’ zijn verbonden door de tak met het label ‘Baan’. Een knoop is door takken verbonden met minstens één andere knoop, maar er is geen bovengrens. Bij een kennisgraaf bouw je de kennis dus in het programma. Op het moment dat er kennis moet worden gecheckt op waarheid, komt dit binnen in de vorm (S,P,O). Hierbij staat het subject op de eerste plaats, de relatie op de tweede plaats en het object op de derde. In ons voorbeeld zou het dus zijn (Mark Rutte, baan, Minister-President). Het algoritme checkt vervolgens of er in de kennisgraaf twee knopen zijn die overeenkomen met het subject en object en kijkt of de tak met het label van de relatie tussen deze knopen loopt. Als al deze drie dingen gevonden kunnen worden, kan er dus worden gesproken over ware kennis. Deze kennis staat dan immers in de kennisgraaf. In het geval dat een van de drie elementen mist, kan het algoritme dus niet met zekerheid zeggen dat de kennis waar is. Wat kan er dan wel worden gezegd over deze kennis? De programmeur beslist hier wat voor strategie het algoritme hanteert om zo’n situatie te verwerken. Een optie is om simpelweg te zeggen dat alle kennis die niet in de kennisgraaf staat, onwaar is. Dit kan soms echter te kort door de bocht zijn, aangezien er kennis bestaat die misschien niet expliciet staat opgeslagen in de kennisgraaf. Er bestaan daarom ook andere, genuanceerdere opties, zoals het algoritme leren logische conclusies te kunnen trekken. Deze opties zijn echter vaak moeilijk te implementeren.
De kennisgraaf lijkt een aantrekkelijke kandidaat voor dit onderzoek. Ten eerste heeft het onderzoek een specifiek onderwerp, waardoor een beperkte hoeveelheid kennis in de graaf moet worden opgenomen. Om uitspraken over het coronavirus te checken is immers niet zoveel kennis nodig als bij het checken van uitspraken over politiek of klimaat, aangezien er daarbij bredere kennis komt kijken. Daarnaast is het een groot voordeel dat de werking van het algoritme inzichtelijk is. Bij machine learning zijn de conclusies die worden getrokken door algoritmes namelijk vaak niet te verklaren door de programmeurs.[1] Een kennisgraaf kan echter makkelijk worden bekeken en mogelijk aangepast.
Echter heeft het opstellen van een kennisgraaf in dit onderzoek ook enkele nadelen. De teksten die ons algoritme moet gaan classificeren, zijn namelijk afkomstig uit verschillende periodes van de coronacrisis. Gedurende deze crisis is de kennis over het virus en de aanpak ervan ook veel veranderd. Neem bijvoorbeeld het aftreden van minister Bruins: na zijn aftreden zouden alle stukken waar hij nog minister van Volksgezondheid wordt genoemd, worden gelabeld als nepnieuws. Op het moment van schrijven was dit echter wel de ‘ware’ kennis. Om dit probleem te vermijden, zou er een soort tijdsdimensie worden toegevoegd aan de graaf, waarbij voor ieder stuk kennis waarvan we weten dat het is veranderd, een soort ‘uiterste houdbaarheidsdatum’ wordt vermeld. Dit zou de kennisgraaf echter verschrikkelijk ingewikkeld maken en zoveel werk vragen van de programmeurs, dat men zich zou kunnen afvragen of het ontwikkelen van het algoritme wel tijd bespaart.
2.3 Naive-Bayes
Waar het bij kennisgrafen een uitdaging is om rekening te houden met onzekerheid, is dat bij de Naive-Bayes methode niet het geval. Naive-Bayes methode van tekstclassificatie is gebaseerd op het theorema van Bayes, een belangrijk theorema binnen de statistiek, dat een formule geeft om de kans van een bepaalde gebeurtenis te bepalen. Je kan hiermee specifiek de kans berekenen dat een bepaalde gebeurtenis A plaatsvindt, gegeven dat een zekere stelling B waar is. Zo wordt deze methode bijvoorbeeld gebruikt om de kans dat iemand kanker heeft (A) te bepalen aan de hand van een bepaald symptoom (B). Binnen NLP is dit handig, aangezien je kan bepalen wat de kans is dat een tekst nepnieuws is (A) gegeven de tekst (B). De Naive-Bayes methode heeft wel een bekend nadeel, namelijk de naïve aanname dat de gebeurtenis A slechts afhangt van B en niets anders. Zo hangt het ontwikkelen van kanker niet slechts af van het vertonen van één symptoom, maar spelen er veel andere variabelen mee. In de praktijk blijkt echter dat deze aanname niet voor grote problemen in nauwkeurigheid zorgt. (Zhou & Zafarani, 2018)
Om Naive-Bayes te implementeren voor tekst-classificatie, moet gebruik worden gemaakt van zogenaamde features. Dit zijn eigenschappen van een tekst, zoals aantal woorden, complexiteit, titel, etc. De programmeurs kiezen enkele van deze features en het algoritme bepaalt de waarde van de features voor elke tekst. Een tekst heeft bijvoorbeeld een hoge complexiteit maar weinig woorden. Vervolgens kijkt het algoritme of er een patroon te vinden is tussen een bepaalde feature en het waarheidsgehalte van een tekst. Zo zou het bijvoorbeeld kunnen dat de kans groot is dat een tekst met nepnieuws relatief kort is en een lage complexiteit heeft. Dit proces heet het trainen van een algoritme. Nadat de training is afgerond, classificeert het algoritme nieuwe teksten op basis van deze patronen. Op dat moment zou een korte tekst door het algoritme eerder worden gelabeld als nepnieuws dan een langere tekst.
Hoewel het veel werk lijkt, is veel van de implementatie van Naive-Bayes al eerder gedaan en makkelijk beschikbaar in Python[2]. Ook is het in een recente studie de beste gebleken van 7 algoritmes die werden getest op hun vermogen om nepnieuws te classificeren. (Zhou & Zafarani, 2018) Tenslotte hebben enkele studenten die meewerken aan dit onderzoek al eerder intensief gewerkt met Naive-Bayes, wat het proces aanzienlijk sneller kan maken.
Echter heeft Naive-Bayes ook een aantal nadelen. Naast het feit dat de nauwkeurigheid zeker beter kan, is dit algoritme een grote ‘black box’. Binnen de informatica duidt dit op een algoritme wat slechts beschreven kan worden in termen van de input en output van het programma, aangezien de specifieke werking van het programma niet te achterhalen is. (Wikipedia, 2020) De patronen die Naive-Bayes ontdekt zijn namelijk niet inzichtelijk voor de programmeurs en de classificatie die wordt gemaakt is dus ook niet uit te leggen. Deze is erg afhankelijk van de data en de features waarop wordt getraind. De training-data moet divers zijn, zodat er niet bij toeval een verkeerd patroon erg sterk wordt vastgelegd in het algoritme. Tegelijkertijd moet de data ook representatief zijn voor de teksten, zodat de juiste patronen wel worden ontdekt. Van de features waarmee wordt getraind, die worden bepaald door het close-reading deel van dit onderzoek, is dus ook niet meteen duidelijk waarom een bepaalde feature de nauwkeurigheid van het algoritme vergroot of juist verlaagt. Kortom, als het werkt is niet uit te leggen waarom.
2.4 Linear support Vector Machine
Voor mij was de Linear Support Vector Machine (LSVM) een nieuw algoritme. Uit de literatuur blijkt echter dat dit algoritme een enorm hoge nauwkeurigheid kan behalen, ook als implementatie om nepnieuws te classificeren, namelijk 92%. (Ahmed, Traore, & Saad, 2017) Ook dit algoritme werkt, net als Naive-Bayes, op basis van features. Iedere tekst krijgt een set features, die als het ware in een grafiek worden gezet. Als voorbeeld neem ik graag een set van twee features, zodat de grafiek makkelijk te illustreren is.
| Figuur 1 |
Figuur 1 (Wikipedia, Support Vector Machine, 2020) geeft een voorbeeld van zo’n grafiek. Stel nu dat de witte datapunten alle teksten zijn met ware informatie en de zwarte datapunten de teksten met nepnieuws. LSVM probeert een lijn te trekken in deze grafiek, zodat van een nieuw datapunt kan worden bepaald tot welke categorie het behoort door te kijken aan welke kant van de lijn het valt. Deze lijn geeft dus de ‘grens’ tussen waar- en nepnieuws weer. In de grafiek zijn drie voorbeelden van zo’n lijn te zien, maar er zijn grote verschillen. Naast het feit dat lijn H1 de twee groepen helemaal niet scheidt, is te zien dat er vele verschillende lijnen te trekken zijn die dit wel doen. Lijn H2 en H3 zijn compleet verschillende lijnen, maar scheiden allebei de twee groepen. Hoe kiest LSVM welke lijn de beste is?
Bij deze beslissing komt erg veel wiskunde kijken, maar het komt erop neer dat LSVM de lijn kiest met de grootste ‘buffer’. Dit houdt in dat er wordt geprobeerd een zo groot mogelijke afstand tussen de lijn en de datapunten te houden. In figuur 1 is dit geïllustreerd met de lijnen die naar H3 lopen. Deze grote buffer zorgt dat een nieuw datapunt met meer zekerheid in een van de categorieën kan worden geplaatst, aangezien het verschil tussen de categorieën groter is dan bij H2.
Door de hoge nauwkeurigheid die LSVM eerder heeft gehaald in een context van nepnieuws, lijkt het zeker een aantrekkelijke toepassing. Daarnaast maakt het sneller nieuwe voorspellingen en kost het minder computergeheugen dan Naive-Bayes. Tenslotte heeft een van de programmeurs van dit onderzoek al eerder gewerkt met SVM’s, waardoor er een mooie kans is voor de anderen om iets nieuws te leren.
Helaas komt er wel een kleine complicatie kijken bij onze implementatie van LSVM: het is enorm ingewikkeld. Het aantal features dat wij gaan gebruiken is namelijk niet twee, maar zal, naar mijn verwachting, minstens tien zijn. Dit betekent dat er dus in minstens tien dimensies gerekend moet worden door het algoritme. Deze complicatie maakt dan ook dat LSVM een langere tijd nodig heeft om te trainen dan Naive-Bayes. Hierbij moet wel worden gezegd dat dit effect groter is naarmate de database groter is. Ik verwacht echter dat onze database niet van zulke grootte gaat zijn dat dit een enorm verschil maakt, maar dat is niet van tevoren met zekerheid te zeggen. Ook is LSVM uiteindelijk, net als Naive-Bayes, een black box.
3 Conclusie
Na deze drie algoritmes kort te hebben toegelicht, is hopelijk duidelijk geworden dat de keuze voor een algoritme niet simpel gemaakt is. Aan de ene kant is er de kennisgraaf, waarbij het proces inzichtelijk blijft voor de programmeurs en welke echt gebaseerd is op de inhoud van een tekst, maar ook grote moeite kost om te implementeren. Aan de andere kant zijn er Naive-Bayes en LSVM, die beide een black box zijn en de tekst niet beoordelen op basis van de inhoud maar op basis van de schrijfstijl, maar waarbij een groot deel van de implementatie al gedaan is en met enkele regels code te gebruiken.
Aangezien kennis rondom de coronacrisis vaak moet worden bijgesteld, zou ik aanraden de kennisgraaf achter ons te laten. Het succesvol vangen van de kennis over het virus en de aanpak ervan in een graaf lijkt een opgave van een enorm formaat en misschien niet eens praktisch te realiseren.
Dan rest ons nog de keuze tussen Naive-Bayes en LSVM, met elk hun eigen voor- en nadelen. Naive-Bayes is zeer bekend bij de programmeurs van dit onderzoek, is erg simpel te implementeren en kost relatief weinig tijd om te trainen, maar de nauwkeurigheid is vaak niet extreem hoog. Daarentegen is LSVM wel een ingewikkeld algoritme, maar kan het een extreem hoge nauwkeurigheid halen, maakt het snellere voorspellingen en biedt het de kans om met een nieuw algoritme te leren werken.
In plaats van een harde keuze maken tussen deze twee algoritmes, zou ik aanraden om beide te implementeren. Hierbij zou Naive-Bayes als eerste geïmplementeerd worden, zodat er in ieder geval een werkend algoritme is. Wanneer dit is bereikt, kan de focus worden verlegd naar LSVM. Als beide algoritmes uiteindelijk werken, kan worden bekeken welk algoritme de hoogste nauwkeurigheid kan krijgen. Dit algoritme zal dan uiteindelijk het ‘eindproduct’ zijn.
Hoe maken we een database?
1 Introductie
Bij dit onderzoek geldt: zonder database, geen onderzoek. Zowel de close- als distant-reading delen van het onderzoek baseren zich op deze database, wat het een belangrijk deel van het onderzoek maakt. De data waar we naar op zoek zijn, zijn teksten over het coronavirus. Hier is nog geen bestaande database van, dus zullen we deze zelf moeten maken. Hierbij komen meteen een aantal vragen kijken, die ik hieronder zal beantwoorden. Daarna zal ik, op basis van de vragen, een plan van aanpak voorstellen.
2 Wat zijn de randvoorwaarden voor de data?
Gelukkig zijn er specifiek voor databases met fake news al negen randvoorwaarden gesteld (Pérez-Rosas, Kleinberg, Lefevre, & Mihalcea, 2017), die wij ook zullen volgen. Volgens deze randvoorwaarden moet de dataset (1) zowel nepnieuws als echt nieuws bevatten, (2) alleen tekst-objecten hebben, (3) te verifiëren zijn in de echte wereld, (4) ongeveer van gelijke lengte en (5) schrijfstijl zijn, (6) nieuws bevatten van binnen een bepaalde tijdsspanne, (7) op dezelfde manier en voor hetzelfde doel zijn geschreven (bv: humor, journaal), (8) openbaar beschikbaar zijn en (9) taal en culturele verschillen in acht nemen.
Aangezien wij alleen Nederlandse data zullen opnemen in onze database, zullen wij ons vooral bezighouden met criteria 1 t/m 8. Verder zullen we proberen (ongeveer) evenveel nepnieuws als echt nieuws in de dataset op te nemen, waarbij we de lijn van vorige onderzoeken voortzetten.
3 Hoeveel data moet het zijn?
Het makkelijke maar onpraktische antwoord op deze vraag is: zo veel mogelijk. Hoe meer data het algoritme heeft om te trainen, hoe kleiner de kans dat het fouten maakt. Een schatting van hoeveel data minimaal nodig is, is voor de onderzoekers wel erg fijn.
Hier lijkt echter geen consensus over te bestaan. De grootte van de datasets in de literatuur verschilt ook sterk. Een onderzoek gebruikte 2000 datapunten (Ahmed, Traore, & Saad, 2017), een ander 50.000 (Resende, et al., 2019). Qua haalbaarheid lijkt het logisch dat wij meer richting de 2000 datapunten gaan dan 50.000, hoewel meer natuurlijk altijd beter is.
4 Hoe verzamelen we de data?
Er zijn veel verschillende manieren om data te verzamelen, maar het belangrijkste verschil lijkt te zijn of het verzamelen handmatig of automatisch plaatsvindt. Aangezien we een zo groot mogelijke database willen creëren, is het nuttig om de tijd die het verzamelen kost te minimaliseren. Het spreekt vanzelf dat er dan zoveel mogelijk automatisch verzameld moet worden.
Gelukkig zijn er veel manieren om automatisch data te verzamelen. In een onderzoek werden bijvoorbeeld meer dan 50.000 WhatsApp berichten automatisch verzameld uit openbare WhatsApp groepen (Resende, et al., 2019). Iets dergelijks zouden wij ook zeker kunnen proberen, mits er in zulke groepen (nep)nieuws wordt gedeeld over het coronavirus. Vergelijkbare strategieën kunnen gebruikt worden om (nep)nieuws te verzamelen van bijvoorbeeld de NOS, het RIVM, Facebook of Twitter.
Aangezien Twitter een platform is waar veel data van vrijwel dezelfde lengte openbaar wordt gedeeld, lijkt het een logisch platform om te beginnen.[3] Op deze manier voldoen we automatisch al aan een aantal van de acht randvoorwaarden.
5 Hoe verwerken we data?
Wanneer we de data hebben verworven, kan het natuurlijk niet meteen door ons algoritme worden verwerkt. Eerst moeten we een aantal stappen zetten om de data te ‘pre-processen’. Ten eerste veranderen we iedere tekst in een set unigrammen, aangezien deze een hogere nauwkeurigheid geven ten opzichte van bigrammen of trigrammen (Zhou & Zafarani, 2018). Verder zullen we van ieder woord de Term Frequency-Inverse Document Frequency (TF-IDF) waarde bepalen. Deze waarde geeft van ieder woord weer hoe significant het is, door te meten hoe vaak het voorkomt in een tekst. Een probleem hiermee is dat veelvoorkomende woorden (zoals ‘de’) een enorm hoge waarde krijgen, terwijl ze niet veel informatie geven en in elke tekst veel voorkomen. Hier komt het IDF deel kijken: de frequentie van een woord in een tekst word afgezet tegen de frequentie van het woord in de hele database. Zo krijg je een meer accuraat idee van welke woorden een verschil maken binnen een tekst.
Uit (Pérez-Rosas, Kleinberg, Lefevre, & Mihalcea, 2017) blijkt dat interpunctie een rol kan spelen in het classificeren van nepnieuws. Hoewel ons close-reading onderzoek moet uitwijzen of wij dit ook gaan meenemen, lijkt het handig om interpunctie niet meteen te verwijderen, zoals vaak standaard is bij NLP databases.
Het is aannemelijk dat er hierna nog enkele stappen moeten worden gezet in het pre-processen van de data. Echter, wat er precies moet gebeuren hangt af van de features die we willen onderzoeken, wat afhankelijk is van de uitkomst van ons close-reading onderzoek. Verdere plannen voor pre-processing zullen hier dus op moeten wachten.
6 Conclusie
Het opstellen van een dataset zal een groot deel van dit onderzoek in beslag nemen. Er moet immers data worden verzameld en (deels handmatig) verwerkt. Tegelijkertijd moet er genoeg tijd overblijven om de algoritmes juist te trainen. Om een zo hoog mogelijke graad van automatiseren en dus tijdwinst te krijgen, zou ik aanraden onze database te baseren op tweets. Dit betekent dat al onze data al ongeveer van dezelfde lengte is en aangezien het ook vrij kort is, zal het makkelijker te verwerken zijn. Gelukkig is er op Twitter zowel veel nepnieuws als echt nieuws te vinden, maar moet iedere tweet wel worden gecheckt op waarheid door een van de onderzoekers.
7 Bibliography
Ahmed, H., Traore, I., & Saad, S. (2017). Detection of Online Fake News Using N-Gram Analysis and Machine Learning Techniques. Springer International Publishing, 127-138.
Pérez-Rosas, V., Kleinberg, B., Lefevre, A., & Mihalcea, R. (2017). Automatic Detection of Fake News. Proceedings of the 27th International Conference on Computational Linguistics (p. 10). New Mexico: Association for Computational Linguistics.
Resende, G., Melo, P., Reis, J. C., Vasconcelos, M., Almeida, J. M., & Benevenuto, F. (2019). Analyzing Textual (Mis)Information Shared in WhatsApp Groups. 11th ACM Conference on Web Science (p. 10). Boston: Association for Computing Machinery.
Wikipedia. (2020, April 16). Black Box. Retrieved from Wikipedia: https://en.wikipedia.org/wiki/Black_box#Computing_and_mathematics
Wikipedia. (2020, April 16). Support Vector Machine. Retrieved from Wikipedia: https://en.wikipedia.org/wiki/Support-vector_machine
Zhou, X., & Zafarani, R. (2018). Fake News: A Survey of Research, Detection Methods, and Opportunities. ACM Comput. Surv 1, 40.
[1] Waarom dit is, zal ik verder toelichten bij de bespreking van de andere algoritmes.
[2] Python heeft zich ontwikkeld tot de standaard taal voor NLP, waardoor veel algoritmes en toepassingen voor NLP erg makkelijk beschikbaar zijn in Python. Vandaar dat we ook in deze taal zullen programmeren.
[3] Wel zal nog moeten worden nagegaan of Twitter regels heeft betreffende gebruik van data.