
Combineren van kwalitatieve en kwantitatieve methoden om nepnieuws te detecteren
Combineren van kwalitatieve en kwantitatieve methoden om nepnieuws te detecteren
1 Inleiding
Steeds meer mensen volgen het nieuws online. Tegenwoordig heeft bijna elke volwassene een smartphone of laptop waarmee het nieuws makkelijk en gratis gevolgd kan worden. Hierdoor neemt het aantal gebruikers dat nieuws ontvangt via de traditionele offlinemethoden, zoals kranten en weekbladen, sterk af.
Uit onderzoek blijkt dat steeds meer mensen nieuws verkrijgen via gerenommeerde nieuwssites zoals nos.nl en nu.nl (Wennekers, de Haan 2017). Bovendien worden sociale media platforms als Facebook en Twitter ook steeds populairder als informatiebronnen.
Er is alleen één probleem met het online verkrijgen van nieuws; iedereen kan (foutieve) informatie over het internet verspreiden. Waar Facebook haar gebruikers meestal met een link naar het originele nieuwsbericht stuurt, wordt het nieuws op Twitter vooral door de gebruiker zelf de wereld in gebracht (PEW Research Center 2012). Door deze user generated content ontstaat nepnieuws, waardoor lezers op het verkeerde been kunnen worden gezet.
In dit paper wordt een plan besproken waarmee nepnieuws onderscheiden zou kunnen worden van feitelijk nieuws. Ten eerste zal kort worden toegelicht wat nepnieuws precies is en waarom het juist nu zo’n groot probleem is. Ten tweede zal er worden gekeken naar het gebruik van kwalitatief onderzoek. Dit zal verschillende teksten op basis van lexicon, syntax en woordkeuze analyseren. Ten derde zal er een kwantitatieve methode aan bod komen. Hiervoor zal een fact-checking programma gebruikt worden dat nep nieuws kan opsporen. Tenslotte zullen deze twee methodes gecombineerd worden, waardoor het algoritme, met de informatie verkregen uit het kwalitatieve onderzoek, een goede schatting zou moeten kunnen maken over welk nieuws echt en welk nieuws nep is.
2 Wat is nepnieuws?
Er is geen duidelijke definitie voor de term nepnieuws. In dit paper zal de definitie worden gebruikt zoals deze door A. Gelfert, onderzoeker aan de Technische Universiteit van Berlijn, beschreven is: nepnieuws is het opzettelijk presenteren van foutieve of misleidende claims als nieuws (A. Gelfert, 2018).
Vanaf de Amerikaanse presidentsverkiezingen in 2016 werd nepnieuws pas echt als een probleem gezien. Er werd toen een onderzoek gedaan naar het bereik van nepnieuws en de resultaten waren erg indrukwekkend. Het bleek dat de twintig meest besproken nepnieuws artikelen 8.711.000 aandelen, reacties en commentaren op Facebook genereerden, tegenover een kleiner totaal van 7.367.000 voor de twintig meest besproken verkiezingsartikelen, geplaatst door gerenommeerde nieuwswebsites (Silverman 2016).
Onderzoek naar nepnieuws kan gedaan worden vanuit vier perspectieven: (1) knowledge-based, dat gefocust is op de foutieve informatie in nepnieuws, (2) style-based, dat zich bezighoudt met de manier waarop nepnieuws geschreven is, (3) propagation-based, gefocust op hoe nepnieuws zich verspreid en (4) credibility-based, dat betrokken is bij de betrouwbaarheid van de auteur en de verspreiders van het nieuws (Zhou en Zafarani, 2018).
Dit stuk zal gefocust zijn op de eerste twee perspectieven. Voor de kwalitatieve methode zal style-based onderzoek worden gedaan en voor de kwantitatieve methode is knowledge-based onderzoek nodig. In het volgende deel zal de style-based methode verder toegelicht worden, waarna ook de knowledge-based methode verder zal worden uitgewerkt.
3 Style-based onderzoek naar nepnieuws
Bij de style-based methode wordt er vooral onderzocht wat de intentie is van bepaald nieuws. Deze informatie kan gebruikt worden bij het achterhalen of bepaald nieuws nep is of niet. De analyse en detectie van misleidingen maakt gebruikt van de style-based methode. Deze studies zijn voornamelijk bezig met (1) deception style theories, waarom de stijl van de inhoud van een tekst kan helpen bij het opsporen van nepnieuws, (2) style-based features and patterns, die nepnieuws kunnen representeren en vastleggen en (3) deception detection strategies die onderzoeken hoe stijl gebruikt kan worden in het detecteren van nepnieuws.
Alle drie zullen nu verder toegelicht worden.
3.1 Deception style theories
Intuïtief zou het logisch zijn als misleidend nieuws qua inhoudsstijl zou verschillen van de waarheid. Dit komt omdat de schrijvers van foutieve informatie vaak mensen willen misleiden met overdreven uitdrukkingen en sterke emoties. Ook forensisch-psychologische onderzoeken hebben aangetoond dat teksten die zijn afgeleid van feiten, verschillen van teksten die gebaseerd zijn op verzonnen verhalen (Siering et al. 2016). Verschillende latere onderzoeken hebben bevestigd dat onderzoeken die inhoudsstijl gebruiken om misleiding op te sporen, goed werken. Het detectie-niveau van deze onderzoeken varieerde tussen de 60% en de 90% (Zhou en Zafarini, 2018).
3.2 Style-based features and patterns
Inhoudsstijl wordt gewoonlijk gerepresenteerd door kwantificeerbare karakteristieken. Deze karakteristieken kunnen worden verdeeld in twee sub-categorieën; attribute-based language features en structure-based language features. Om te begrijpen wat de verschillen zijn worden beide groepen hieronder toegelicht.
Attribute-based language features zijn meestal gebaseerd op de eerdergenoemde deception style theories. De kenmerken van nieuwsberichten kunnen worden gegroepeerd in tien categorieën; kwantiteit, complexiteit, onzekerheid, subjectiviteit, niet-directheid, sentiment, diversiteit, informaliteit, specificiteit en leesbaarheid. Deze attribute-based language features zeggen veel over de waarheid van een tekst en zijn erg verklaarbaar. Er zitten echter ook nadelen aan deze aanpak. De kenmerken zijn namelijk vaak moeilijk te kwantificeren. Specifieke kenmerken hebben vaak een extra herhaling van detectie nodig en dat kost veel tijd.
Om te bepalen welke categorieën van kenmerken het meest relevant zijn voor de detectie van nepnieuws, hebben X. Zhou en R. Zafarani verschillende onderzoeken naast elkaar uit gezet (Tabel 1) (Zhou en Zafarini, 2018). In deze tabel is te zien dat misleidende berichten hogere niveaus van kwantiteit, niet-directheid en informaliteit tonen, terwijl diversiteit en specificiteit juist lager scoren bij foutieve informatie. Toekomstige onderzoeken kunnen met behulp van deze informatie preciezere style-based detectie programma’s schrijven.
Tabel 1: Patronen van misleidende attribute-based language features

Structure-based language features beschrijven de inhoudsstijl van informatie op vier taalniveaus; (1) lexicon, (2) syntax, (3) semantiek en (4) dialoog. Het kwantificeren van structure-based language features berust vooral op Natural Language Processing (NLP). NLP is een sub gebied van taalkunde, informatica en kunstmatige intelligentie, dat zich bezighoudt met de manier waarop computers grote hoeveelheden natuurlijke taalgegevens verwerken en analyseren (Liddy, 2001). Op lexicon-niveau is de belangrijkste taak van NLP om de frequentie van letters, woorden enz. te beoordelen. Op syntax-niveau houdt het zich bezig met de grammatica van zinnen. Op semantisch niveau gaat het om de betekenis van verschillende woorden en zinnen. En tenslotte traceert NLP op dialoog-niveau de verschillende retorische relaties tussen woordgroepen en zinsdelen. In nepnieuws detectie studies zeggen structure-based language features minder over de waarheid van een tekst, maar het berekenen van de kenmerken is relatief eenvoudig ten opzichte van attribute-based language features.
3.3 Deception detection strategies
Er is nog weinig onderzoek beschikbaar over deception detection strategies, maar het is een erg opkomende aanpak in het opsporen van nepnieuws.
De meeste onderzoeken gebruiken supervised-learning technieken, waarbij een programma een database bezit met gelabelde training data. Aan de hand van de voorbeelden in deze database, zou het programma nieuwe input-data moeten kunnen labelen als ‘nep’ of ‘normaal’.
Er zijn echter twee problemen met deze manier van onderzoeken. Ten eerste is het aantal gelabelde voorbeelden in de database relatief klein. Dit komt doordat het handmatig labelen van voorbeelden lang niet zo snel gaat als de snelheid waarin nieuwe informatie wordt gecreëerd op sociale media. Ten tweede is het moeilijk om een perfecte database te maken, aangezien mensen slecht zijn in het identificeren van nepnieuws. Sociale psychologie- en communicatiestudies tonen aan dat het menselijk vermogen om nepnieuws te detecteren slechts een paar procent beter is dan toeval. De gemiddelde nauwkeurigheid van 1000 deelnemers aan meer dan 100 experimenten is 54% (Rubin, 2010). In volgende onderzoeken zou semi-supervised learning dan ook een grote rol kunnen spelen bij het verbeteren van nepnieuws detectie programma’s. Hierbij is niet alle data gelabeld, maar is er ook nog een groot deel ongelabelde data. Op deze manier kan een programma zichzelf meer aanleren, dan alles van een ‘supervisor’ na te bootsen.
Aan de hand van style-based onderzoek kunnen teksten dus kwalitatief geanalyseerd worden. Bij deze strategie bestuderen onderzoekers bepaalde kenmerken in de inhoudsstijl. Hierbij kan gekozen worden voor het analyseren van attribute-based language features of structure-based language features. Later zal duidelijk worden op welke manier deze gegevens kunnen helpen om nepnieuws te detecteren.
4 Knowledge-based onderzoek naar nepnieuws
Net zoals bij style-based onderzoek, gaat het bij knowledge-based onderzoek over het bestuderen van de inhoud van een tekst. Bij de knowledge-based methode gaat het echter over de waarheid van een tekst, waar het bij style-based studies gaat over de intentie van de schrijver van een tekst.
Om de waarheid van een tekst te achterhalen, gebruikt de knowledge-based methode de fact-checking strategie. Het doel van deze strategie is, zoals de naam al zegt, het checken van feiten in een tekst. Er zullen twee verschillende methoden worden besproken voor fact-checking. Ten eerste zal kort de traditionele vorm aan bod komen, waarna de automatische vorm toegelicht zal worden.
4.1 Handmatige fact-checking
Bij deze vorm van fact-checking worden teksten gecontroleerd door mensen. Dit kan zowel door experts gedaan worden (expert-based) als door groepen mensen (crowd-sourced). Ook deze twee verschillende benaderingen zullen kort toegelicht worden.
Expert-based fact-checking is afhankelijk van experts per domein. Deze manier van fact-checking wordt vaak uitgevoerd door een kleine groep van erg betrouwbare experts. Hierdoor zijn de resultaten erg nauwkeurig, maar kost de methode ook een hoop geld. Bovendien stijgt het aantal beoordeelde gegevens een stuk langzamer dan het aantal te controleren nieuws.
Crowd-sourced fact-checking is afhankelijk van een groot aantal individuen die zullen optreden als fact-checkers. In vergelijking met expert-based fact-checking is deze methode erg moeilijk te controleren. Daarnaast zijn de resultaten minder geloofwaardig en precies, doordat mensen beoordelen vanuit hun eigen perspectief. Daarentegen staat wel dat deze methode heel wat sneller gaat doordat het aantal fact-checkers een stuk groter is. Deze vorm van controleren is echter nog steeds niet snel genoeg om de grote hoeveelheid aan nieuwe gegevens bij te houden.
4.2 Automatische fact-checking
Om de snelheid van opkomend te controleren nieuws bij te kunnen blijven, zijn er automatische technieken ontwikkeld. Deze maken gebruik van Information Retrieval (IR) en Natural Language Processing (NLP). In afbeelding 1 is globaal te zien hoe een automatisch fact-checking proces in zijn werk gaat (Zhou en Zafarani, 2018). Zoals je ziet is de procedure verdeeld in twee stadia; (1) fact-extraction en (2) fact-checking. Bij fact-extraction wordt er een knowledge-base gemaakt. Deze is opgebouwd uit gegevens van het internet, die na een data-opruiming, alleen nog maar uit feiten bestaan (Pawar et al. 2017). Bij fact-checking wordt vervolgens de te controleren input vergeleken met de knowledge-base om te bepalen of het nepnieuws is of niet. Beide fases zullen nader worden toegelicht.
Afbeelding 1: Proces automatische fact-checking
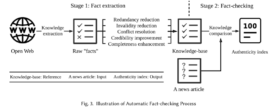
Zhou en Zafarini, 2018
Fact-extraction verloopt op zijn beurt weer in verschillende stappen. Eerst wordt er grove informatie van het internet gehaald. Deze gegevens zijn vaak verouderd, onbetrouwbaar of onvolledig. Om tot een bruikbare knowledge-base te komen, moet deze informatie grondig opgeruimd worden. De procedure zal duidelijk uiteengezet worden.
Het verkrijgen van informatie over internet wordt ook wel knowledge extraction genoemd. Onderzoekers kunnen op twee manieren gegevens verzamelen van het internet; ze kunnen één bron gebruiken (single-source), of meerdere bronnen (open-source). Single-source knowledge extraction haalt zijn informatie van één betrouwbare bron (zoals nos.nl). Deze methode is erg efficiënt, maar resulteert vaak in incomplete kennis (Auer et al. 2007). Open-source knowledge extraction daarentegen, gebruikt gegevens van meerdere bronnen. Dit leidt tot minder efficiënte informatie, maar de uiteindelijke gegevens zijn completer (Dong et al. 2014).
De data die op dit punt is verzameld, is nog verre van af. Zo kan de informatie overbodig, ongeldig, tegenstrijdig, onbetrouwbaar en incompleet zijn. Om deze gebreken te verhelpen moeten de volgende taken uitgevoerd worden (de precieze technieken worden niet toegelicht in dit paper):
Ten eerste wordt het oplossen van entiteiten (Steorts et al. 2016) gebruikt om overbodige informatie te verwijderen. Deze methode probeert in de knowledge-base woordgroepen te zoeken die naar dezelfde entiteit verwijzen (Culotta en McCallum, 2005). Zo verwijzen ‘Barack Obama’ en ‘Barack Hussein Obama’ naar dezelfde persoon, terwijl het verschillende woordgroepen zijn.
Ten tweede wordt tijdregistratie gebruikt om verouderde data bij te werken. Soms worden gegevens na een bepaalde tijd ongeldig. Zo is ‘Barack Obama wordt president van de Verenigde Staten’ tegenwoordig niet meer geldig. Deze informatie moet dan verwijderd of bijgewerkt worden (Bollacker et al. 2008).
Ten derde wordt kennisfusie toegepast om tegenstrijdige informatie aan te pakken. Het probleem van tegenstrijdige informatie komt vooral voor wanneer er open-source knowledge extraction wordt toegepast. In dit geval wordt er gekeken naar de betrouwbaarheid van de websites waar de gegevens vandaan zijn gehaald. Hiermee kan uiteindelijk bepaald worden welke data verwijderd moet worden en welke niet (Esteves et al. 2018).
Ten vierde is er de evaluatie van waarheid, die wordt gebruikt om de geloofwaardigheid van gegevens te verbeteren. Ook bij deze methode worden de bronnen waarvan data is verzameld onderzocht op betrouwbaarheid. Hierbij wordt niet alleen de inhoud van de bronnen beoordeeld, maar ook de links naar andere websites die door de bronnen worden gegeven worden goed onderzocht (Dong et al. 2015).
Tenslotte wordt voorspelling van relaties toegepast om nieuwe feiten af te leiden. Wanneer data van één enkele bron wordt gebruikt, is de informatie vaak verre van compleet. Het is dus noodzakelijk om nieuwe informatie af te kunnen leiden van al bekende informatie om tot een complete knowledge-base te komen (Nickel et al. 2016).
Door het volgen van deze vijf stappen kan een goede knowledge-base gecreëerd worden die we kunnen gebruiken in de volgende fase.
Fact-checking gaat na het maken van de knowledge-base de te controleren gegevens beoordelen. Hiervoor zal de input vergeleken moeten worden met de feiten uit de knowlegde-base. Dit wordt onderzocht door middel van SPO-triples. Dit is een set van (Subject, Predicate, Object) trio’s, die uit de knowledge-base worden gehaald. Wanneer er een trio gevonden wordt in de te onderzoeken gegevens, wordt er gekeken of er in de knowledge-base eenzelfde trio bestaat. Dit gebeurt in drie stappen:
Ten eerste moet de entiteit worden gelokaliseerd. In deze stap wordt het subject van trio gelinkt aan een entiteit. Hierin is het weer belangrijk dat twee verschillende woordgroepen naar dezelfde entiteit kunnen wijzen. Entity resolution technieken kunnen gebruikt worden voor het matchen van subjects aan entiteiten (Getoor en Machanavajjhala, 2012).
Ten tweede moet de relatie tussen subject en object geverifieerd worden. Het trio (Obama, beroep, president) is bijvoorbeeld alleen waar als dit trio ook bestaat in de knowledge-base. Als dit niet het geval is, dan worden de gegevens (1) beschouwd als onwaar (close world assumption) of (2) verder gecontroleerd in de laatste stap (Reiter, 1981).
In de laatste stap worden de gegevens die nog niet als waar of onwaar zijn bestempeld nog verder beoordeeld. Hiervoor wordt de voorspelling van links gebruikt, waarmee nieuwe informatie kan worden afgeleid van al bekende gegevens. De resultaten die hieruit komen worden weer vergeleken met de feiten uit de knowledge-base. Op deze manier kan uiteindelijk besloten worden of de informatie waar of onwaar is.
Door middel van knowledge-based onderzoek kunnen gegevens handmatig en automatisch gecontroleerd worden op waarheid. Bij de automatische methode voor fact-checking wordt op een kwantitatieve manier gecheckt of input nepnieuws is of niet. In het volgende gedeelte zal toegelicht worden hoe we deze kwantitatieve methode nog meer kunnen gebruiken.
5 Combineren van kwalitatief en kwantitatief onderzoek
De aanleiding voor het combineren van kwalitatief en kwantitatief onderzoek is dat de verschillende methoden verschillende krachten hebben. De kwalitatieve methode doet onderzoek naar variatie van data op een kleinere schaal en de kwantitatieve methode doet onderzoek naar hoeveelheden van bepaalde kenmerken op een grotere schaal. Door ze samen te voegen, breng je het vermogen van beide methoden samen in één onderzoek. Om kwalitatief en kwantitatief onderzoek te combineren moet een onderzoeker zichzelf twee vragen stellen (Morgan, 1998):
5.1 Welke methode wordt de belangrijkste methode in het onderzoek en welke zal aanvullend zijn?
De onderzoeker zal eerst moeten bepalen of de kwalitatieve of de kwantitatieve methode als hoofdmethode zal dienen. Er bestaat natuurlijk de kans dat beide methoden even belangrijk worden beschouwd, wat leidt tot problemen (Morse, 1991). De twee onderzoeken zouden in dat geval in een samenhangend verband moeten verlopen, waarna er een derde stap nodig is om de twee te verbinden. Bovendien kan de informatie, gevonden in de verschillende onderzoeken, tegenstrijdig zijn.
Een praktischere methode is om een enkele strategie te kiezen als hoofdmethode en de ander te gebruiken als complementaire strategie. Om deze beslissing te maken, moet de onderzoeker nagaan welke methode de resultaten zal verkrijgen die het belangrijkst zijn om de onderzoeksvraag te beantwoorden. Als de hoofdmethode is gekozen, zal de onderzoeker moeten bepalen op welke manier de andere methode kan helpen bij het vergrijgen van de beste resultaten.
5.2 Zal de aanvullende methode voorafgaan aan de hoofdmethode, of zal de aanvullende methode volgen op de hoofdmethode?
Wanneer de hoofdmethode en de aanvullende methode zijn gekozen, moet de volgorde van de twee worden bepaald. Ook hier is weer de belangrijkste vraag: hoe kunnen de twee verschillende methoden het best verbonden worden om optimale resultaten te verkrijgen? Bij het beantwoorden van deze vraag is het belangrijk om na te denken over de hoofdmethode.
In het begin van een onderzoek is het belangrijkste doel om de effectiviteit van de hoofdmethode te optimaliseren. Dit kan door een inleidende methode te gebruiken, die de data voor de hoofdmethode kan perfectioneren. Tegen het eind van een project is het doel om de resultaten die verkregen zijn te maximaliseren. In dit geval kan een onderzoek beëindigd worden door het gebruiken van een tweede methode, die de bestaande resultaten kan optimaliseren.
De volgorde van de twee methodes hangt dus niet zoveel af van of ze kwalitatief of kwantitatief zijn. Het gaat er vooral om of de aanvullende methode een grotere bijdrage kan leveren voorafgaand aan de hoofdmethode, of volgend op de hoofdmethode.
Nu er een duidelijker beeld geschetst is over hoe kwalitatief en kwantitatief onderzoek het best gecombineerd kunnen worden, zullen beide vragen beantwoord worden aan de hand van het kwalitatieve en kwantitatieve onderzoek dat eerder besproken is.
Eerst zal er bepaald moeten worden welke methode de belangrijkste methode wordt. Het doel van het onderzoek is om nepnieuws te kunnen detecteren. Hiervoor kunnen we als hoofdmethode het best de kwantitatieve strategie nemen, aangezien deze grote hoeveelheden data snel kan analyseren. De kwalitatieve methode kan gebruikt worden als aanvullende methode.
Hierna zal de onderzoeker moeten bepalen of de kwalitatieve methode voorafgaand of na de kwantitatieve methode zal gebeuren. In het onderzoek naar nepnieuws zal de kwalitatieve methode erg handig van pas komen om de knowledge-base voor het kwantitatieve onderzoek te creëren. Dit betekent dat het kwalitatieve onderzoek voorafgaand aan de hoofdmethode zal plaatsvinden.
Op deze manier kan de kwalitatieve methode door middel van style-based onderzoek verschillende teksten analyseren op kenmerken in de inhoudsstijl. De resultaten van dit onderzoek kunnen daarna in de knowledge-base van de kwantitatieve methode gebruikt worden, waarna deze de data uit zijn knowledge-base zal vergelijken met de te controleren data. De resultaten uit dit laatste onderzoek zullen aantonen welke gegevens nepnieuws zijn en welke niet.
6 Conclusie
Nepnieuws is tegenwoordig een erg groot probleem. Iedereen kan foutieve informatie verspreiden over sociale media en het menselijke vermogen om nepnieuws te detecteren is erg klein. In dit paper is een methode besproken om nepnieuws te kunnen detecteren aan de hand van kwalitatief en kwantitatief onderzoek. Kwalitatief onderzoek analyseert teksten door te kijken naar kenmerken in inhoudsstijl. Het kwantitatieve onderzoek gebruikt deze resultaten om zijn knowledge-base op te bouwen. Hierna kan de input data vergeleken worden met de feiten uit de knowledge-base, waardoor gecontroleerd zal worden welke input nepnieuws is en welke niet.
7 Geraadpleegde bronnen
Ali, M. & Levine, T. (2008). The language of truthful and deceptive denials and confessions
Anderson, E. T. & Simester, D. I. (2014). Reviews without a purchase: Low ratings, loyal customers, and deception
Auer S., Bizer, C., Kobilarov, G., Lehmann, J., Cyganiak, R. & Ives, Z. (2007). Dbpedia: A nucleus for a web of open data
Bollacker, K., Evans, C., Paritosh, P., Sturge, T. & Taylor, J. (2008). Freebase: a collaboratively created graph database for structuring human knowledge
Bond, G. D. & Lee, A. Y. (2005). Language of lies in prison: Linguistic classification of prisoners’ truthful and deceptive natural language
Braun, M. T. & Van Swol, L. M. (2016). Justifications offered, questions asked, and linguistic patterns in deceptive and truthful monetary interactions
Culotta, A. & McCallum, A. (2005). Joint deduplication of multiple record types in relational data
Derrick, D. C., Meservy, T. O., Jenkins J. L., Burgoon, J. K. & Nunamaker J. F. (2013). Detecting deceptive chat-based communication using typing behavior and message cues
Dong, X. L., Gabrilovich, E., Heitz, G., Horn, W., Lao, N., Murphy, K., Strohmann, T., Sun, S. & Zhang, W. (2014). Knowledge vault: A web-scale approach to probabilistic knowledge fusion
Dong, X. L., Gabrilovich, E., Murphy, K., Dang, V., Horn, W., Lugaresi, C., Sun, S. & Zhang, W. (2015). Knowledge-based trust: Estimating the trustworthiness of web sources
Esteves, D., Reddy, A. J., Chawla, P. & Lehmann, J. (2018). Belittling the Source: Trustworthiness Indicators to Obfuscate Fake News on the Web
Fuller, C. M., Biros, D. P. & Wilson, R. L. (2009). Decision support for determining veracity via linguistic-based cues
Gelfert, A. (2018). Fake news: a definition
Getoor, L. & Machanavajjhala, A. (2012). Entity resolution: theory, practice & open challenges
Hancock, J. T., Curry L. E., Goorha, S. & Woodworth, M. (2007). On lying and being lied to: A linguistic analysis of deception in computer-mediated communication
Humpherys, S. L., Moffitt, K. C., Burns, M. B., Burgoon J. K. & Felix, W. F. (2011). Identification of fraudulent financial statements using linguistic credibility analysis
Liddy, E. D. (2001). Natural Language Processing.
Matsumoto, D. & Hwang, H. C. (2015). Differences in word usage by truth tellers and liars in written statements and an investigative interview after a mock crime
Morgan, D. L. (1998). Practical strategies for combining qualitative and quantitative methods: applications to health research
Morse, J. M. (1991). Approaches to qualitative-quantitative triangulation
Newman, M.L., Pennebaker, J. W., Berry, D. S. & Richards, J. W. (2003). Lying words: Predicting deception from linguistic styles
Nickel, M., Murphy, K., Tresp, V. & Gabrilovich, E. (2016). A review of relational machine learning for knowledge graphs
Pawar S., Palshikar, G. K. & Bhattacharyya, P. (2017). Relation Extraction: A Survey
Pew, R.C. (2012). In changing news landscape, even television is vulnerable. Trends is news consumption: 1991 – 2012
Reiter, R. (1981). On closed world data bases
Rubin V. L. (2010). On deception and deception detection: Content analysis of computer- mediated stated beliefs
Siering et al. (2016). Detecting fraudulent behavior on crowdfunding platforms: The role of linguistic and content-based cues in static and dynamic contexts
Silverman, C. (2016). This analysis shows how viral fake election news stories outperformed real news on Facebook
Steorts, R. C., Hall, R. & Fienberg, S. E. (2016). A bayesian approach to graphical record linkage and deduplication
Wennekers, A. & de Haan, J. (2017). Nederlanders en nieuws, gebruik van nieuwsmedia via oude en nieuwe kanalen
Zhou, L., Burgoon, J. K., Nunamaker, J. F. & Twitchell, D. (2004). Automating linguistics-based cues for detecting deception in text-based asynchronous computer-mediated communications
Zhou, L. & Zenebe, A. (2008). Representation and reasoning under uncertainty in deception detection: A neuro-fuzzy approach
Zhou, X. & Zafarani, R. (2018). Fake News: A Survey of Research, Detection Methods, and Opportunities